


Footnotes are deceptively simple. They sit quietly at the bottom of a page, easy to overlook, but in the documents that matter most to enterprises, they carry an outsized share of the actual information. A single footnote in a 10-K filing can restate revenue recognition assumptions. A footnote buried in a legal contract can redefine the scope of an indemnification clause. Actuarial tables routinely push their most important qualifications into fine print that lives below the main content. For anyone building automated workflows around these documents, footnotes aren't a nice-to-have, they're essential.
The challenge is that footnotes break the linear reading order of a page, and most extraction tools respond by either ignoring them, merging them into surrounding text, or stripping out the reference linkage that makes them meaningful. Teams end up writing fragile post-processing logic to recover information that should have been captured cleanly from the start.
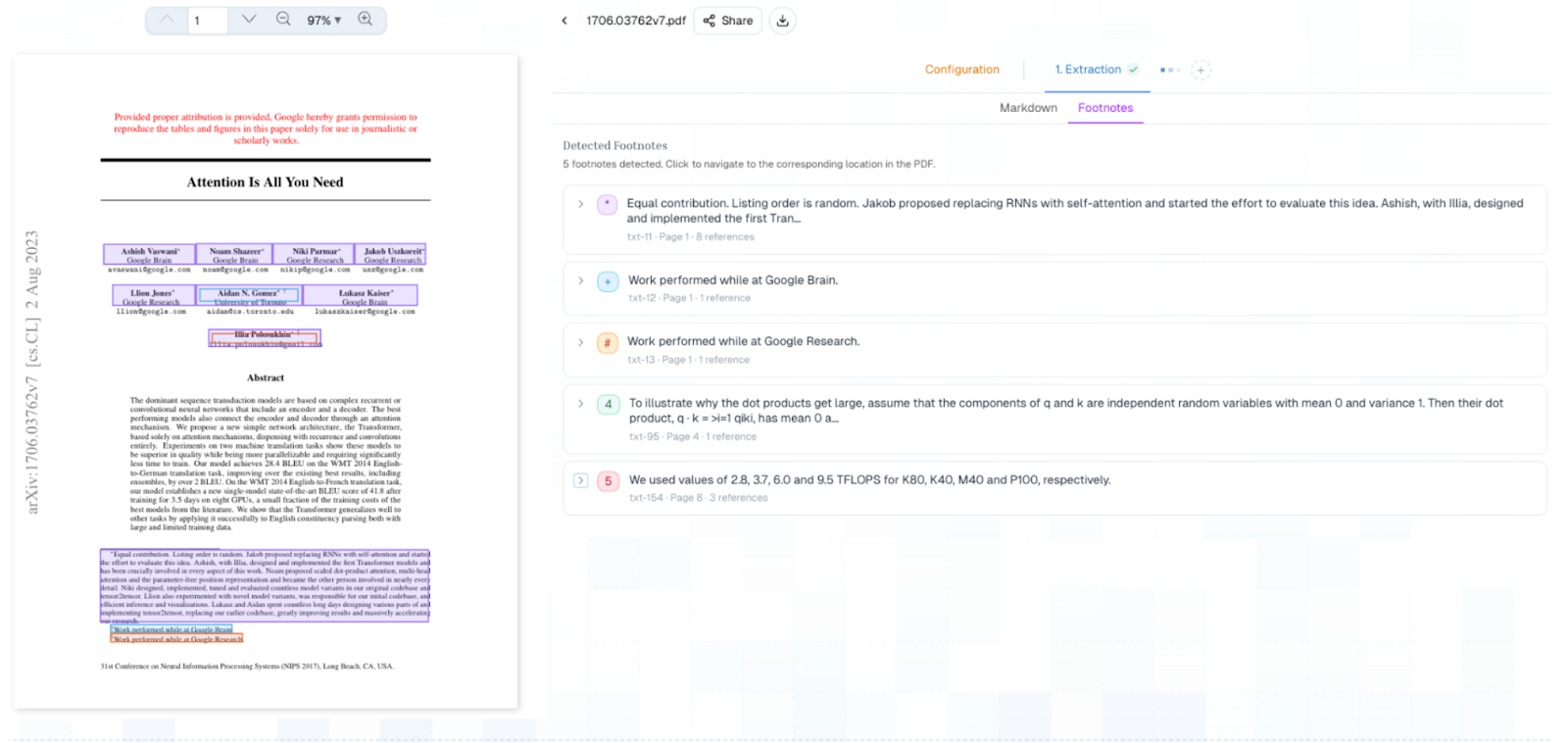
What's new
After working closely with a number of our enterprise customers to refine this capability in production, Pulse now offers footnote extraction as a generally available feature across the platform. Every footnote in a processed document is returned as a distinct, structured object with three key properties: the reference marker that identifies it, the full footnote text, and the positional metadata that links it back to exactly where it was cited in the body of the document.
This means the relationship between a superscript marker in a paragraph or table cell and the corresponding footnote content at the bottom of the page is fully preserved in the output, giving you the ability to reconstruct the original reading context programmatically without any manual mapping or post-processing.
How it works
Footnotes are automatically detected and extracted as part of the standard Pulse output whenever they appear in a document, with nothing to configure on your end. The feature works across PDFs, scanned documents, and digitally native files, and it handles the edge cases that come up most often in enterprise document workflows:
Multi-page footnotes. When a footnote begins on one page and continues on the next, Pulse stitches the content together and returns it as a single, complete object rather than splitting it across page boundaries.
Footnotes inside tables. Financial filings and regulatory documents frequently embed footnotes within table cells. Pulse extracts these alongside the table structure itself, so both the tabular data and its qualifying footnotes are captured in a single pass.
Variable formatting. Documents often use different footnote styles across sections, switching between numeric markers, symbols, or lettered references. Pulse normalizes these into a consistent output format regardless of how they appear in the source.
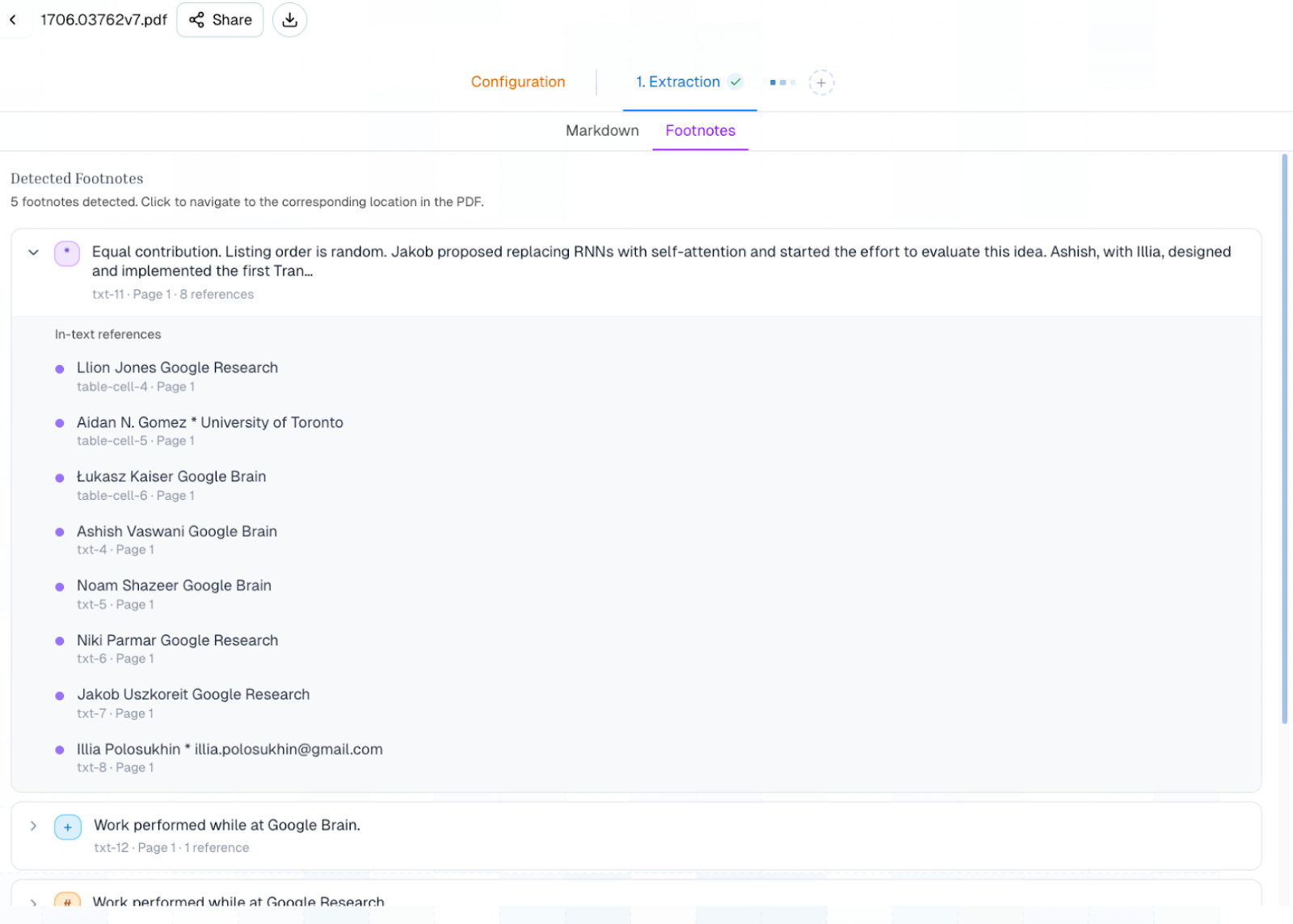
What this looks like in practice
Before footnote extraction, teams processing documents like SEC filings or insurance contracts would typically run their extraction pipeline, get back structured content that was missing footnotes or had them jumbled into body text, and then layer on custom regex or heuristic logic to find, isolate, and re-link the footnote content after the fact. That post-processing was brittle, hard to maintain across document types, and often the first thing to break when a new format showed up.
Now, footnotes come through as structured data from the start, arriving linked to their references, complete across page boundaries, and ready for LLM context windows, database ingestion, or compliance workflows without any intermediate cleanup step.
Get started
Footnote extraction is live now for all Pulse platform users. Visit the documentation for the updated output schema, and reach out to the team if you have questions about integrating this into your existing pipeline. Try it here.

