


In April 2026, Surge released GDP.pdf, a benchmark built on the documents that real businesses depend on: claims packets, technical manuals, clinical papers, securities filings, construction punch lists, rating manuals, and scientific tables. It asks a simple question: can a frontier model answer an expert-level question when the answer is buried inside a real professional PDF?
The public set covers 100 document tasks across ten domains, with 1,275 rubric criteria in total, an average of about thirteen graded requirements per task.
Our view is that the bottleneck is not only model intelligence. It is evidence quality. Professional PDFs have structure, and if the retrieval layer breaks that structure, the model starts from a distorted version of the document. This blog from the Pulse team walks through what GDP.pdf tests, the two fixed Pulse approaches we evaluated, and the improvement in the capability of retrieval pipelines when we action on the data layer the models reason over.
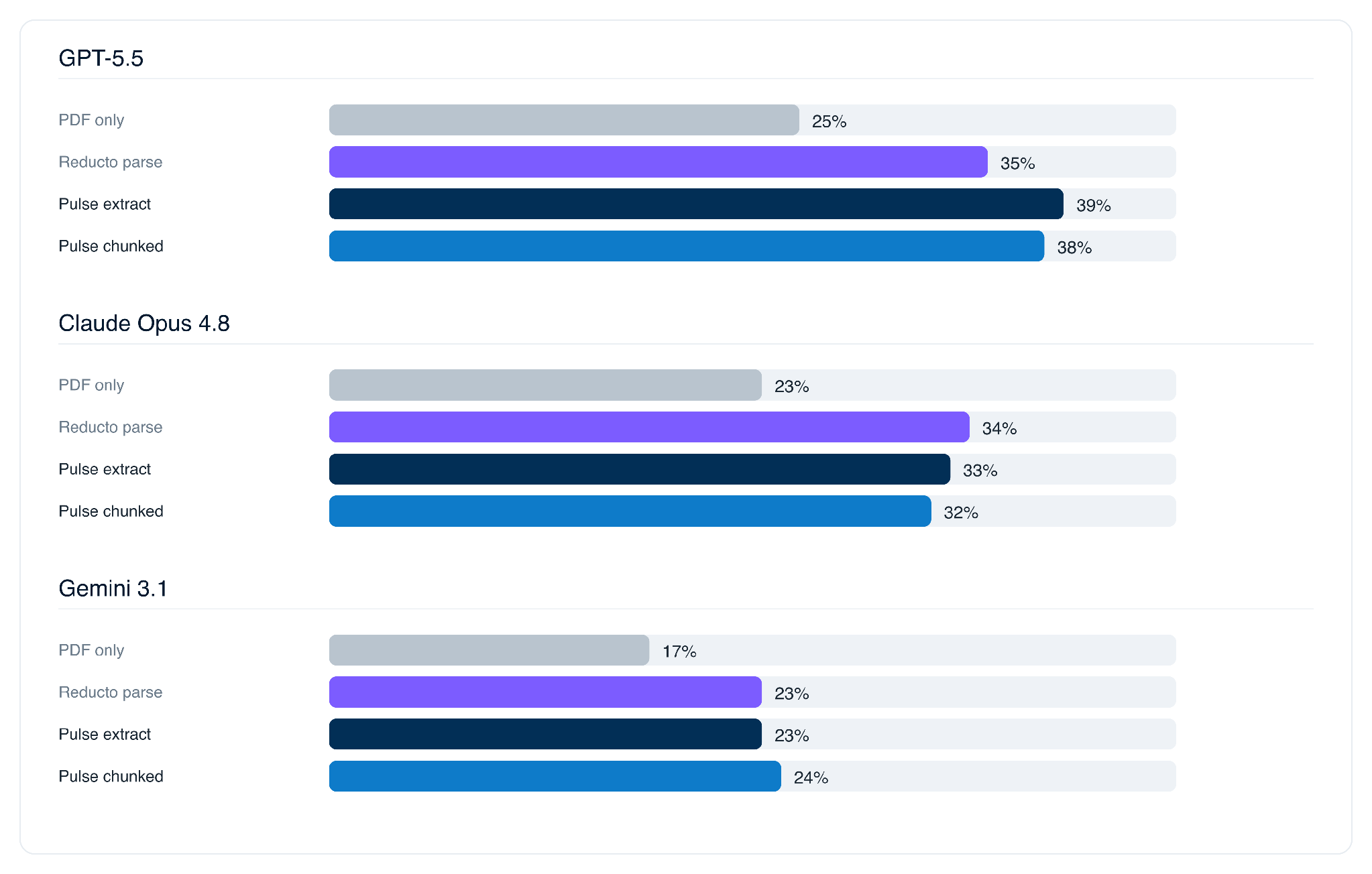
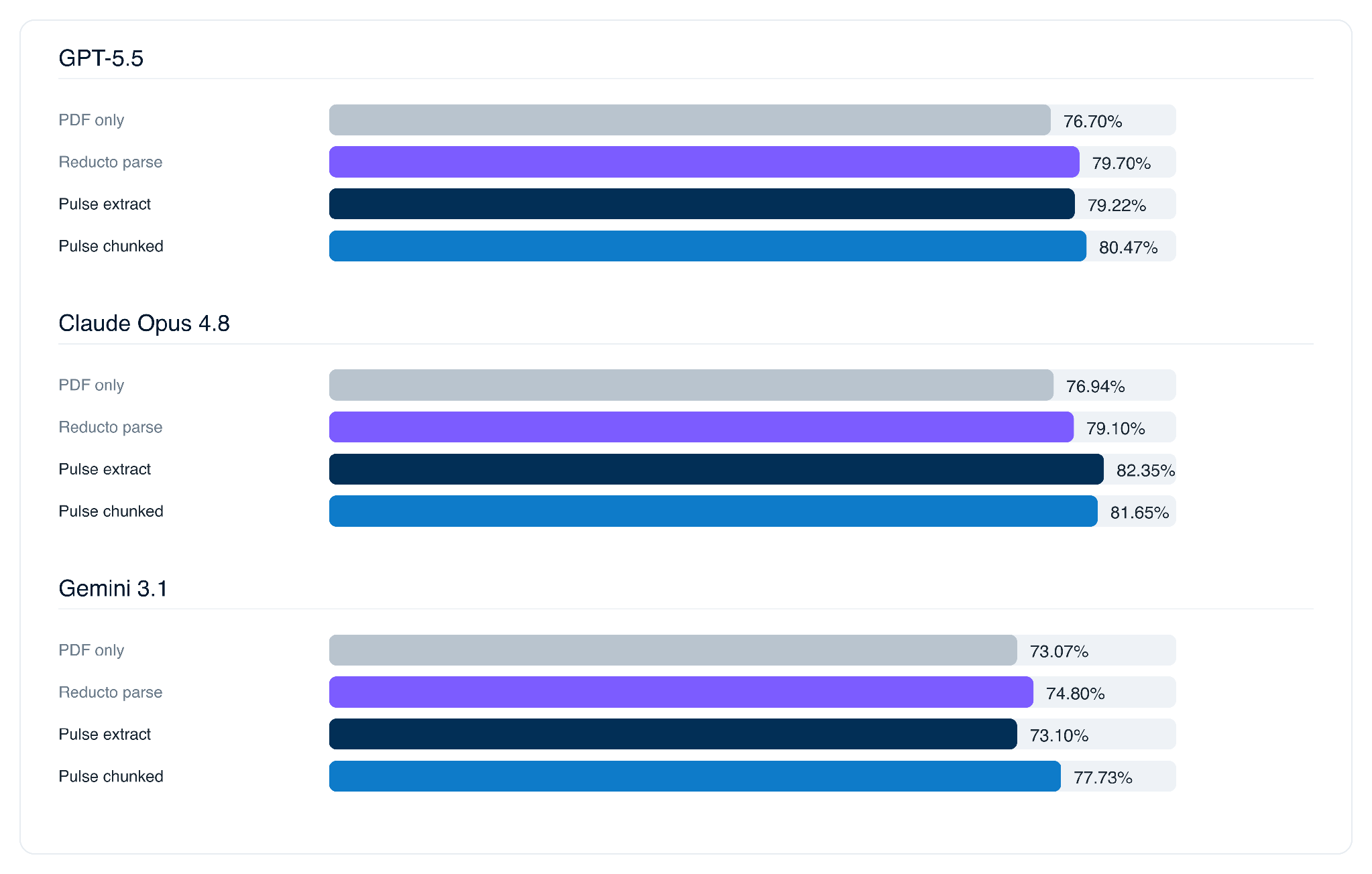
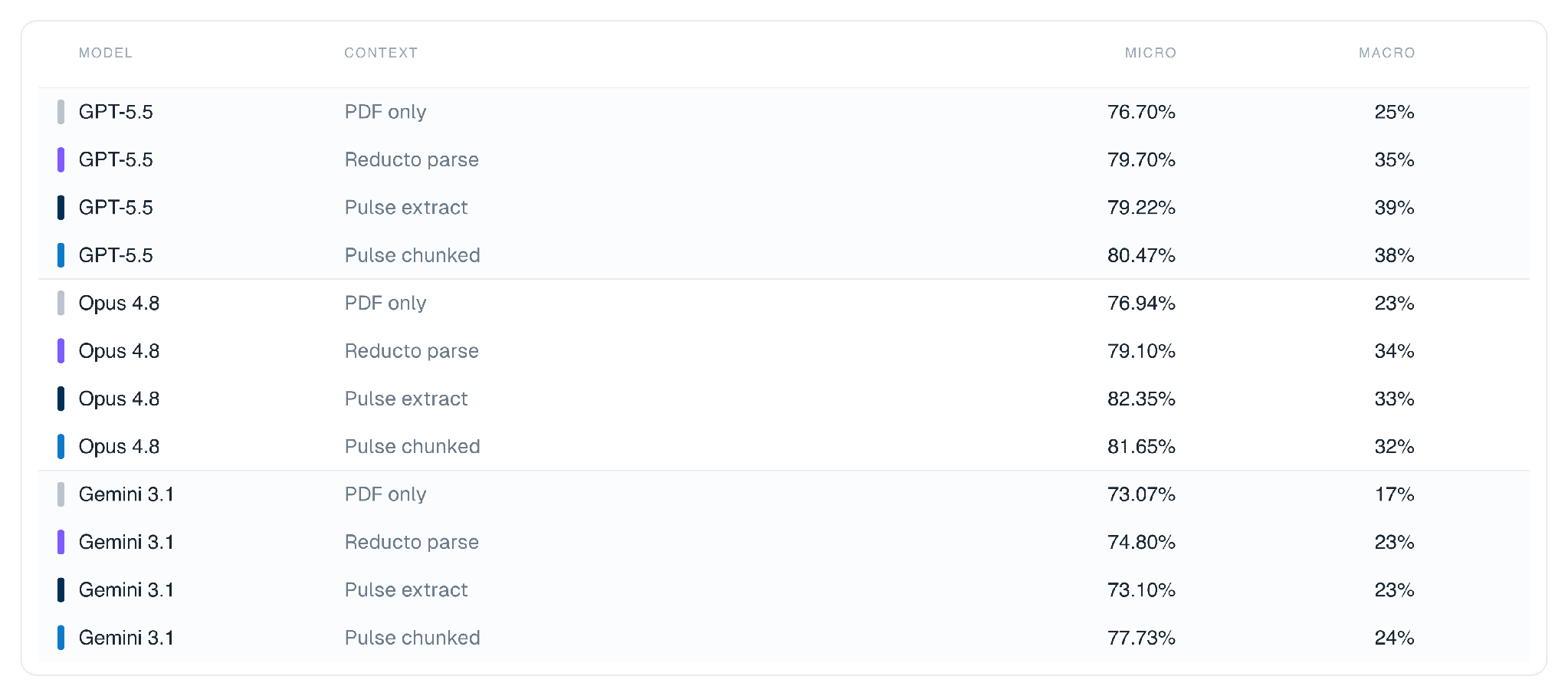
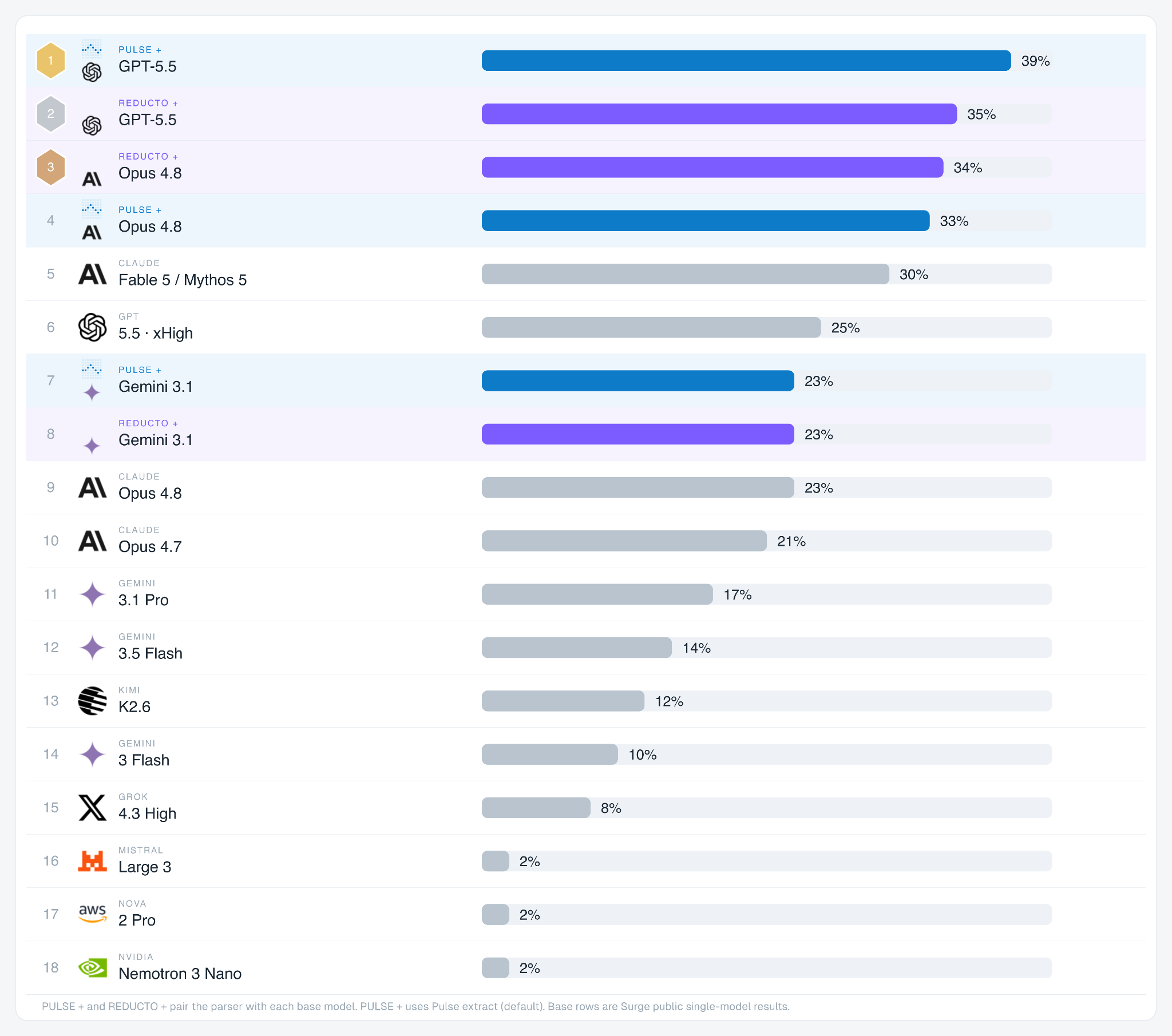
Surge reported no LLM cleared 30% on whole-task accuracy (the strongest public model reached 25%). With Pulse as the default data extraction layer, those same models average nearly 32% with a high of 39%.
What GDP.pdf actually tests
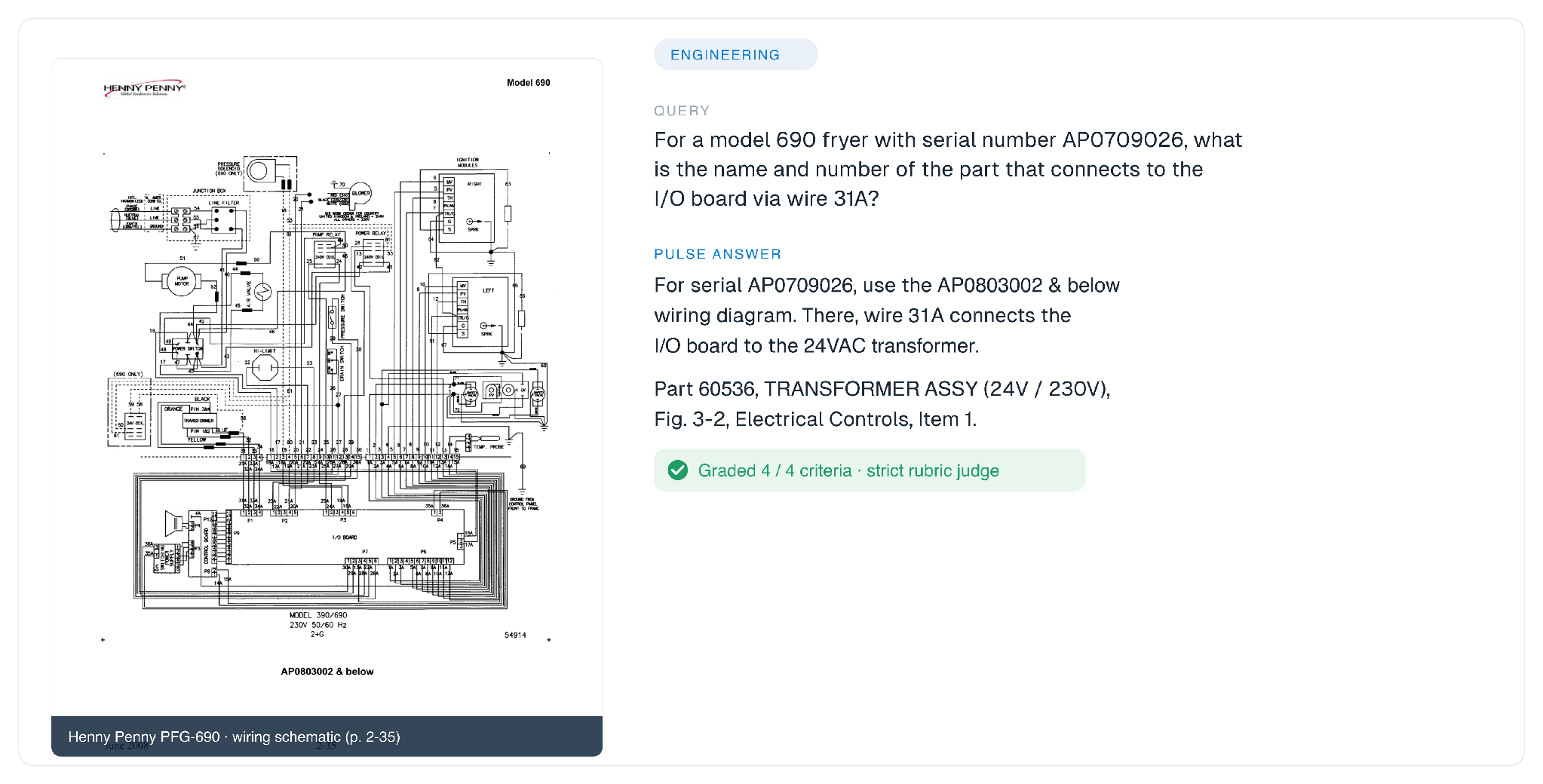
GDP.pdf is not an OCR benchmark. It is a test of whether a model can find, preserve, and reason over the structure of a professional document. Two real examples make the point. In one engineering task, the answer to "which part connects to the I/O board via wire 31A?" lives inside a dense wiring schematic, and the rubric also penalizes citing the wrong diagram for the wrong serial range.
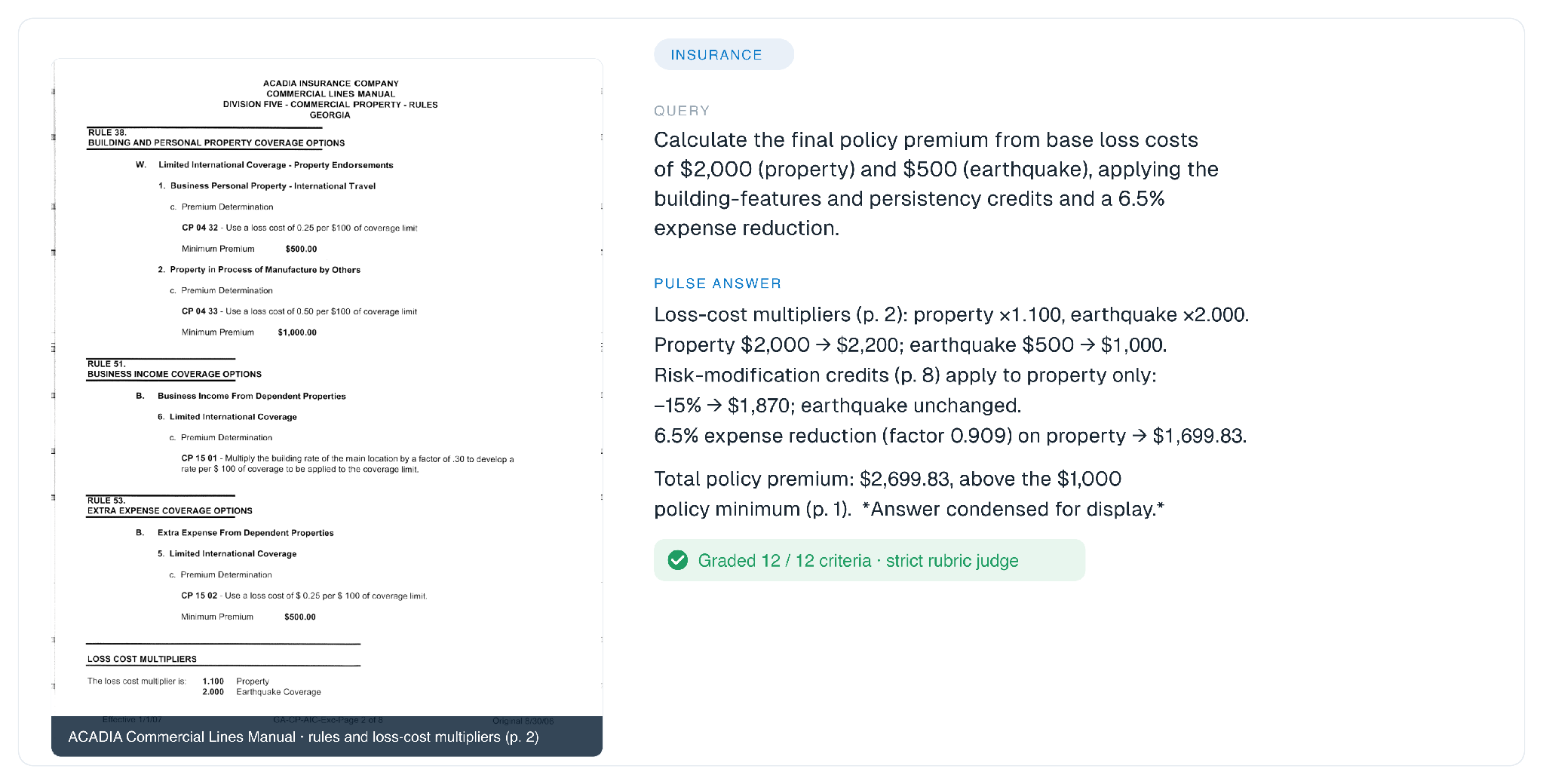
In another insurance task, the final policy premium has to be built step by step from loss-cost multipliers, credits that apply to some coverages but not others, and an expense-reduction factor, each on a different page of a commercial rating manual.
The approach: two ways to give a model better data
We evaluated two fixed configurations. Both start from the original PDF and a Pulse parse of it, both use the same three answerer models, and both use the same strict rubric judge. They differ only in how the parsed document is delivered to the model.
The default Pulse extract sends the original PDF plus the full Pulse markdown extraction to the answerer model. It tests the direct value of a structured representation, with text, tables, figure descriptions, layout cues, and page references sitting alongside the original document.
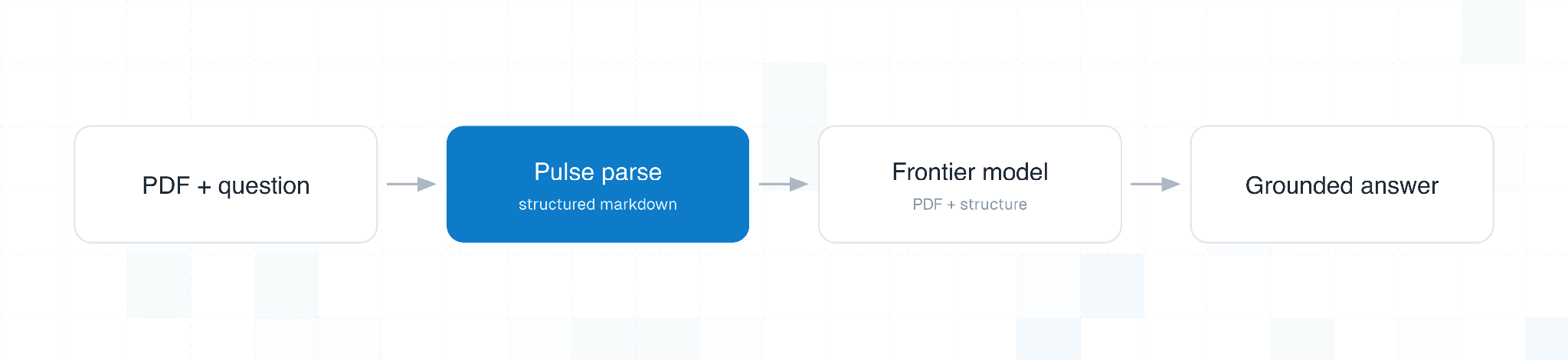
The Pulse chunked retrieval starts from the same Pulse markdown, then splits it deterministically into page-ordered chunks. Each chunk is distilled into compact checklist evidence, covering values, labels, dates, units, rows, columns, and page references, and the answerer model receives the original PDF plus the complete evidence pack.

Results
On the three-model average, the pattern is consistent. A better evidence layer raises the ceiling for every model, on both metrics.
Micro is criteria-level accuracy, the share of individual rubric requirements satisfied. Macro is whole-task success, the share of tasks where every requirement is met, which is far harsher because one missed detail fails the entire task.
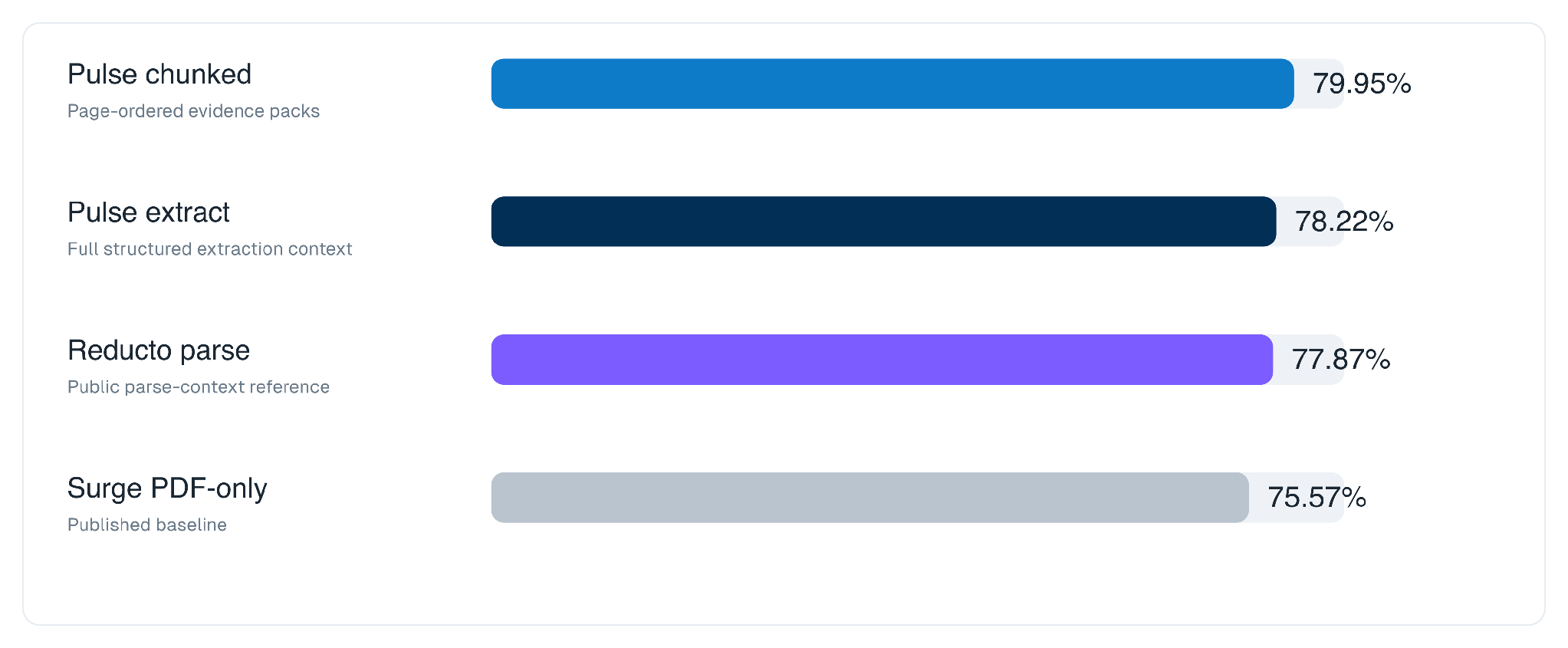
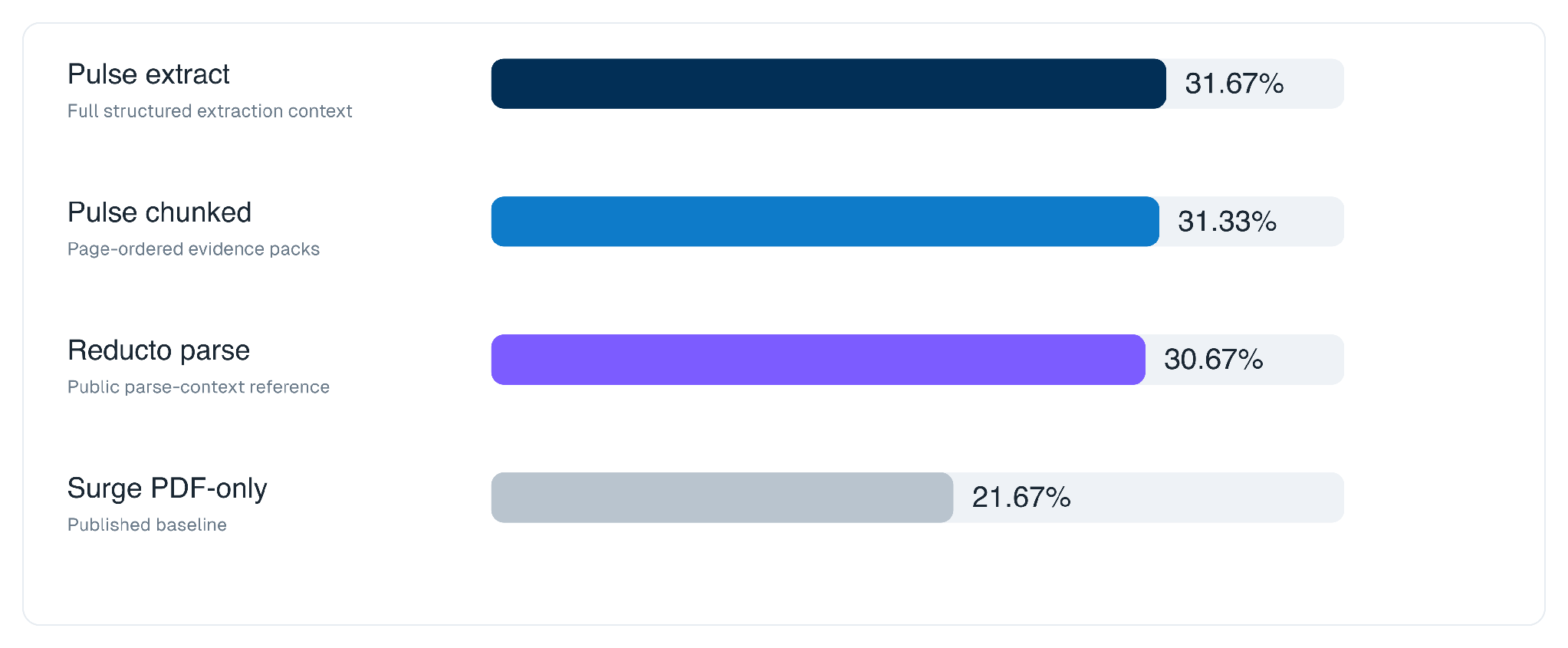
Pulse extract gives the strongest whole-task result. Pulse chunked gives the strongest criteria-level result. Both clear the Surge PDF-only baseline by a wide margin on macro, roughly ten points of whole-task success.
The per-model view shows where the gains come from. Every model improves over its PDF-only baseline. Pulse chunked lifts Gemini's criteria-level accuracy the most, while Pulse extract produces the best whole-task numbers on GPT-5.5.
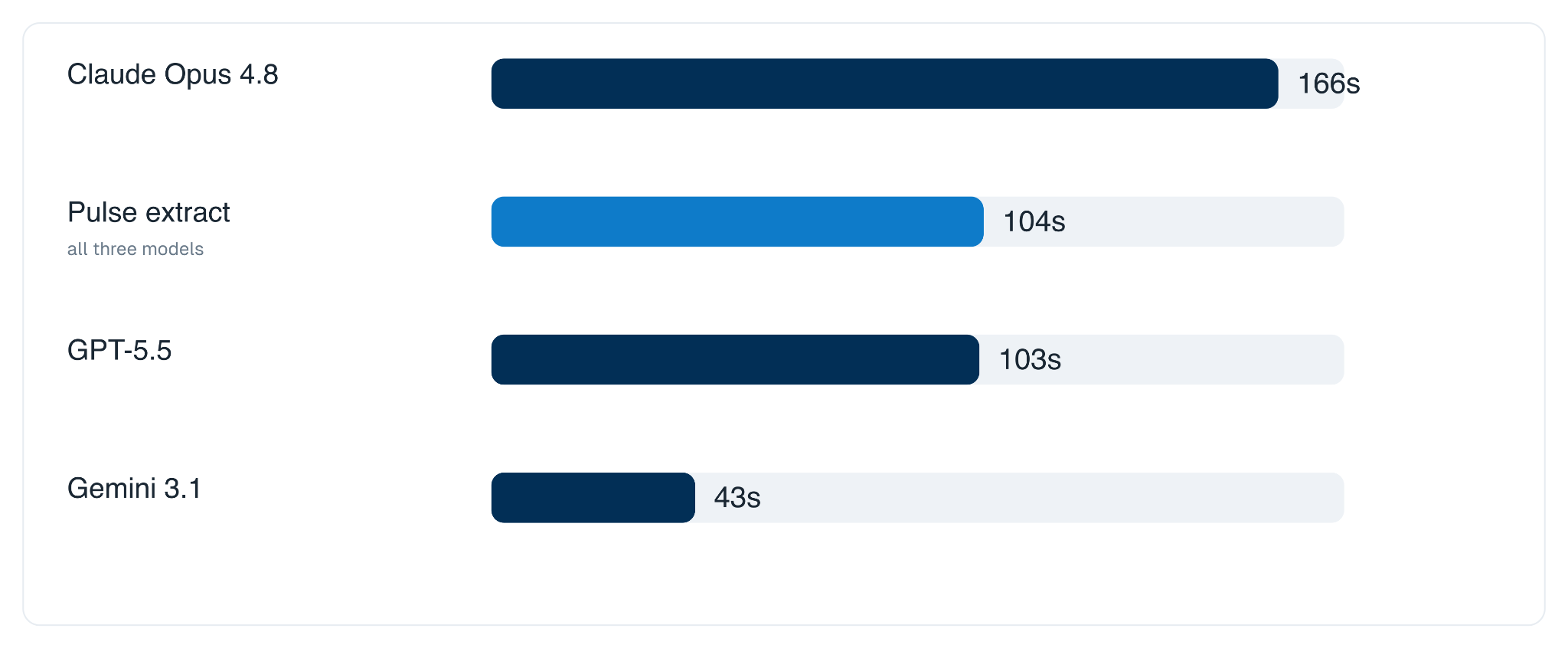
Latency
Pulse answers from a single pass. In our runs it averaged about 104 seconds per task.
What actually changed
The model is still doing the reasoning. Pulse changes the data it reasons over.
Many GDP.pdf failures are not failures of reasoning in the abstract. They are failures of evidence preservation: the wrong row, the wrong page, a dropped footnote, a unit detached from a number, a diagram label missed, or a table split into incoherent chunks. Giving an LLM the most accurate extraction of the document results in many more cases passing the test.
Evaluation deep-dive

We used the public Surge GDP.pdf dataset, with 100 document tasks and 1,275 rubric criteria. Each task was answered by one of three frontier models, GPT-5.5, Claude Opus 4.8, and Gemini 3.1, given the original PDF plus Pulse context.
Grading uses a strict rubric judge. For every Pulse run we used the same judge: DeepSeek V4 Pro. The two evaluations are independent. We hold the judge fixed across all Pulse runs so that differences come from the evidence layer, not the grader.
Where this shows up in production
The benchmark is a proxy for everyday enterprise work, and the same retrieval layer shows up across industries.
Private equity. Internal search across CIMs, lender reports, board decks, and diligence folders, where the goal is not just finding a passage but finding the right number, attached to the right table row, with a source reference that survives review.
Utility and engineering. Construction diagrams, plan sets, and revision-heavy PDFs where the answer hides in callouts, legends, and dense tables.
Energy and resources. Well files, scanned historical records, handwritten notes, and P&IDs, where the inputs are messy but the downstream questions are precise.
Bottom line
Frontier models are increasingly capable reasoners, but enterprise document work fails when the evidence layer is weak. Pulse improves that layer. It turns a messy PDF into structured, page-grounded context, and lets the model reason over the right facts. That is what production document pipelines actually need.

