


Spanned table merging, one of our most-used enterprise features, is now generally available through the Cloud API.
Tables that span multiple pages are among the most common structures in financial and legal documents, and they've historically been among the hardest to extract reliably. The challenge isn't identifying that a table exists; it's recognizing that what appears on page 7 and what continues on page 8 are the same object. Most extraction tools don't make that connection. They return fragments, and the work of reassembling them falls on whoever is downstream.
The screenshots below show this in practice. The source document is a quarterly global operations report containing a regional revenue breakdown explicitly labeled "Table 1 of 3," a table that starts on the first page and continues across the next. Without any manual configuration, our platform identifies the specific table tags with bounding box coordinates as belonging to the same structure, merges them, and surfaces a single unified table in the output panel, labeled clearly as "Merged Table (2 tables merged)."
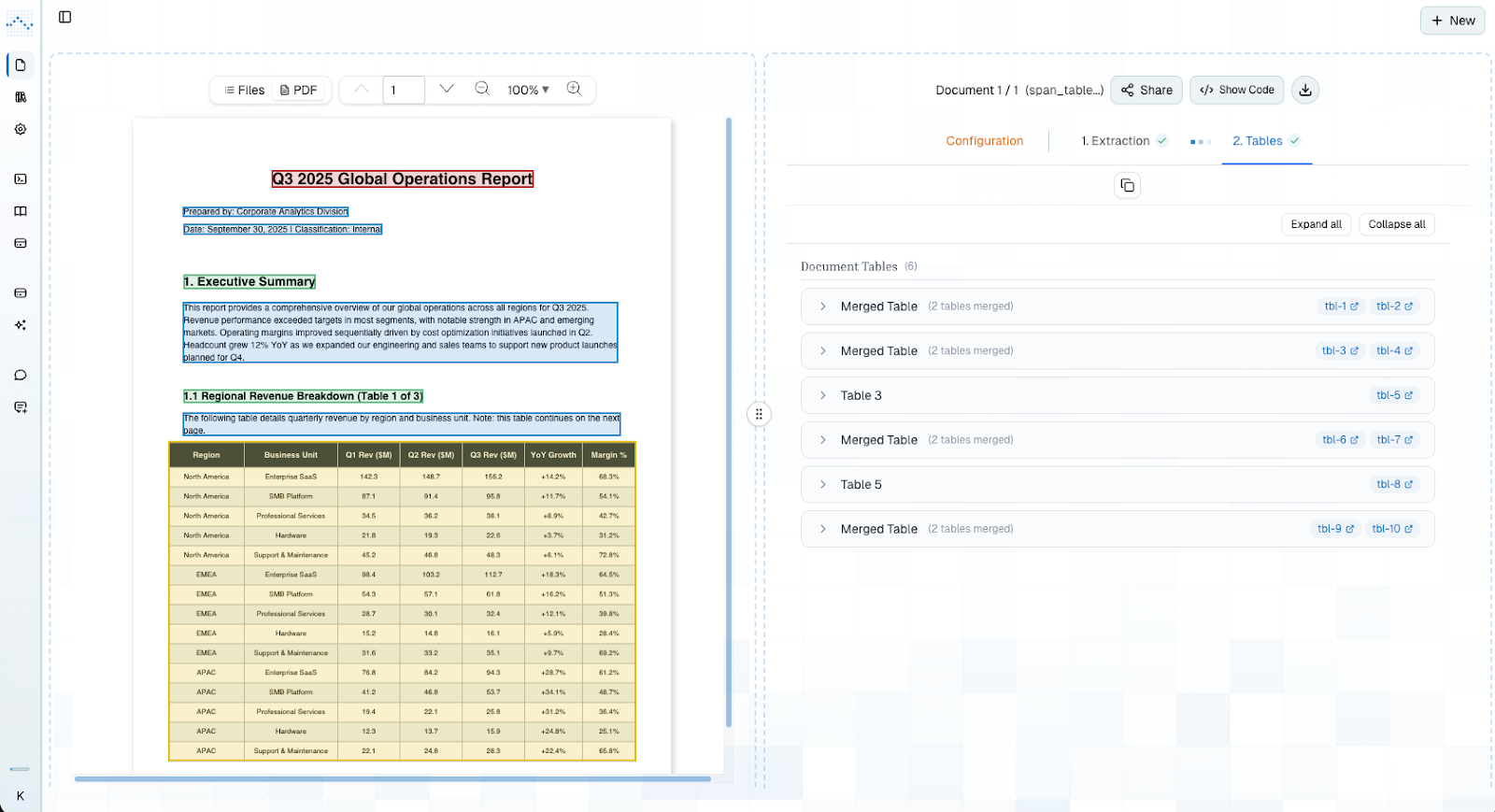
What makes this possible is that our detection logic operates across both the structural layout of the page and the semantic content of the tables themselves. The platform isn't simply looking for visual proximity or matching column counts; it's evaluating whether the content of one table is a continuation of another. That distinction matters when documents don't behave consistently, which in practice is most of the time.
Underpinning this is a model we've trained specifically on a proprietary dataset with an unusually high concentration of spanned tables drawn from the kinds of complex, real-world documents our customers process every day. That training distribution is what sets our approach apart. General-purpose extraction models rarely encounter spanned tables in sufficient volume or variety to develop robust detection, which means they default to structural heuristics that break down under the formatting inconsistencies common in enterprise documents.
Because our model has been trained on this data at scale, it has developed a much richer representation of what table continuation actually looks like across different document types, layouts, and languages, allowing it to make merging decisions that are grounded in the underlying data rather than surface-level pattern matching.
The result, shown in the second screenshot, is a clean, complete table with all regions, all columns, and every row intact, exactly as it was intended in the source document.
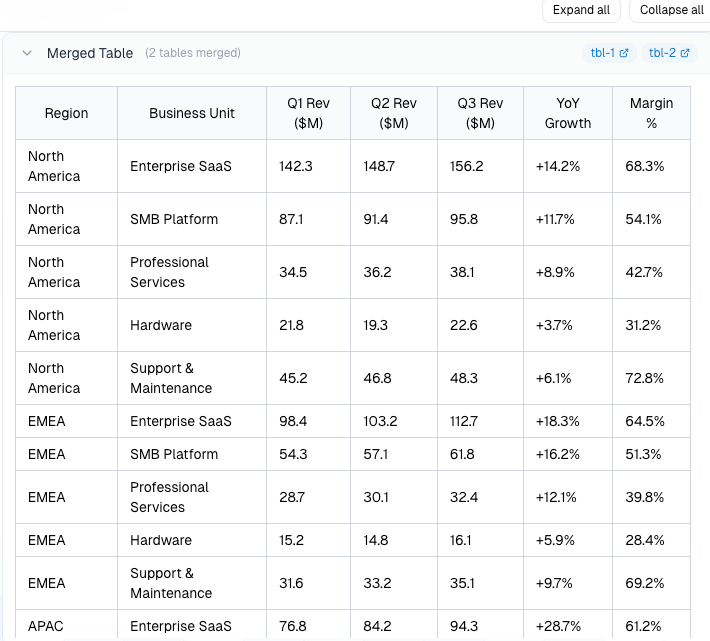
For teams building on top of document data, this raises the baseline for what extracted output looks like. Pipelines don't need to account for broken tables as a routine condition. The data that comes back is complete, and analysis can begin from there.
Spanned table merging is available now through the Cloud API. Log in at the link here to get started. API Docs here.

