


Most operators believe they solved the well log problem a decade ago, back when a scanning vendor came through, the file room was emptied into a storage system, and a project that had loomed for years was quietly closed, leaving the records digital, searchable in the loosest sense of the word, and safely backed up so that everyone could move on. The trouble is that a scanned well log is an image of a document rather than the data inside it, and for the decisions that actually depend on the subsurface record, that distinction turns out to be the whole game.
A well log, a type log, a structure map, or a wellbore schematic carries its meaning in places that a scan preserves only as pixels. The depth track running down the left margin governs everything to its right, the curves in a triple combo log mean nothing without the scale headers that frame them, and a cross section communicates through the vertical relationships between formations rather than through any sentence a reader could ever search for. When those documents are reduced to flat images, the information is technically retained and operationally lost, because nothing in the file can be queried, compared, or fed into a model without a person first sitting down to read it back out by hand.
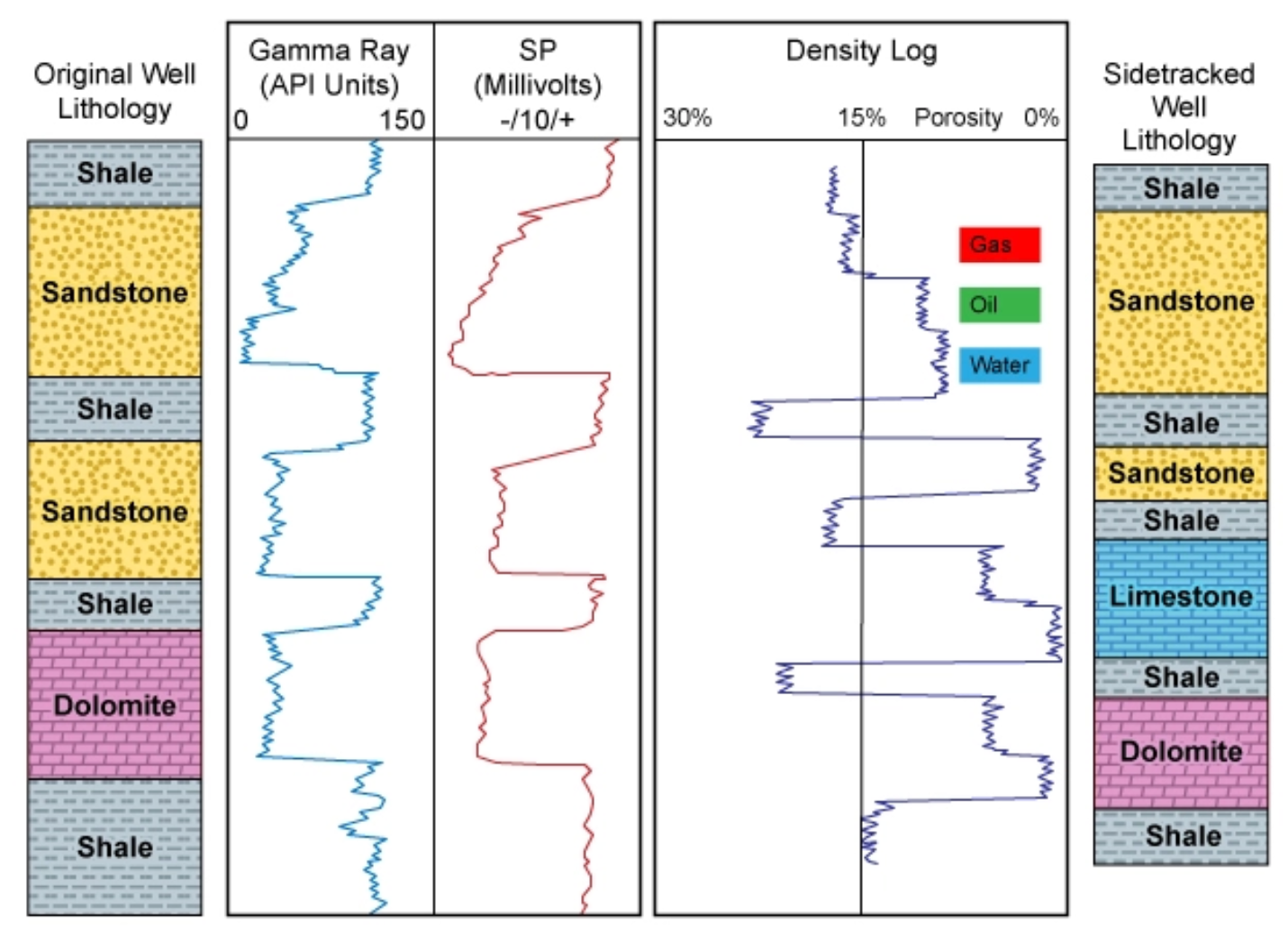
The partial fix that most teams reached for made the gap easier to overlook. Curve data was converted into LAS files wherever a digital record already existed, which covered the most recent and most standardized wells reasonably well and created the comfortable impression that the archive as a whole had been brought forward. The older wells, the acquired acreage, the historical logs that survive only as paper or microfilm, and above all the visual documents that were never curves to begin with, meaning the schematics and the hand-annotated cross sections and the structure maps, were all left exactly where they started. The part of the subsurface record that was hardest to extract was therefore also the part that got skipped, which means the gap in coverage tracks almost perfectly with the documents that carry the most interpretive weight.
This matters because the subsurface archive is not dead storage but a living reference, given that a log shot in the 1960s is still consulted when a team evaluates infill potential or revisits a mature field for secondary recovery, and unlike almost any other category of business document these records have an active working life measured in decades rather than years. An operator that cannot read its own historical logs as data is not merely missing an efficiency, it is making capital decisions on a fraction of the evidence it already owns and once paid to preserve.
The cost of the gap shows up most sharply in the work that depends on scale. Evaluating a play means comparing hundreds or thousands of logs across a basin to find the patterns that no single well will ever reveal, and that comparison only becomes possible once every log has been read into a consistent and structured form. The same dynamic governs acquisition diligence, where a buyer inheriting another operator's document chaos has weeks rather than months to understand what the acreage truly contains, and where the speed and accuracy of reading the subsurface record feeds directly into what the assets are judged to be worth. In each case the bottleneck is not interpretation, which is the work geoscientists are actually paid to do, but the manual transcription that has to happen before any interpretation can begin.
Closing that gap requires reading these documents the way the people who created them do, which means recognizing that a depth column governs a track, that a curve is meaningless without its scale, and that a schematic encodes relationships rather than prose. This is precisely the kind of visual and spatial understanding that conventional optical character recognition was never built to handle and that general-purpose models manage only unreliably, and it is the problem that Pulse's vision-language models are built to solve. Pulse reads well logs, schematics, and subsurface maps as structured, queryable, and traceable data, with the source-level provenance that subsurface work demands, and it does so across the faded, handwritten, and decades-old records that make up the bulk of the archive rather than only the clean modern subset that earlier projects already captured.
The well log problem was never really solved so much as it was scanned, filed, and deferred, and the value locked inside that record has been waiting ever since for tools that could finally read it the way an interpreter does. Those tools now exist, and the operators that reach into the archive first will be the ones making decisions on the full weight of what they already know.
.svg)
