


Most table extraction benchmarks test on clean, well-bordered, single-language grids, the kind of tables that look great in a demo but rarely show up in the documents enterprises actually need to process. The reality of production document intelligence is messier: tables that span multiple pages, encode structure through whitespace rather than borders, mix languages and scripts, nest sub-tables inside cells, or use visual indicators like colored dots in place of text.
PulseBench-Tab is a new benchmark built to close this gap. It evaluates table extraction on the kinds of documents that Fortune 500 companies, financial institutions, and research organizations encounter every day, and it is designed around the structural edge cases that separate production-grade extraction from everything else rather than optimizing for academic datasets with predictable layouts.
Our team will walk through five of the hardest tables in the benchmark, explain what makes each one structurally challenging, and show what Pulse actually produces when it processes them. For each example, we include the source document alongside Pulse's extracted output, so you can evaluate the results for yourself.
What Makes a Table "Hard"
Before diving into specific examples, it's worth establishing a taxonomy of the failure modes that most extraction models struggle with, because these aren't obscure corner cases but rather patterns that appear constantly in real-world enterprise documents.
Implicit structure. Many of the hardest tables encode their layout through whitespace, alignment, and visual convention rather than explicit borders or grid lines. A regression results table in an academic paper, for instance, uses column alignment and indentation to communicate which coefficients belong to which model specification, with no cell borders at all. Models that rely on line detection or grid inference fail here because there is no grid to find.
Nested and hierarchical headers. Financial documents frequently use multi-level column headers where "FY22" contains sub-columns like "Min," "Target," and "Max." Extracting the data correctly requires understanding parent-child relationships between header cells, not just reading left to right across a single row.
Mixed cell content types. A single table might contain numeric values with significance stars, standard errors in parentheses, categorical text, boolean indicators encoded as colored dots, and empty cells that carry semantic meaning (a dash is not the same as a blank). Models that treat every cell as a text extraction problem lose the structural semantics that make the data usable downstream.
Right-to-left and multilingual text. Arabic, Hebrew, and other RTL scripts create bidirectional layout challenges where the visual reading order of columns may conflict with the logical data order. CJK characters introduce variable-width rendering and vertical centering within cells. Models trained primarily on English-language documents often fail silently on these layouts, producing outputs that look plausible but are structurally wrong.
Hierarchical row grouping and repeating blocks. Many financial tables group rows under a parent label that appears only once, leaving subsequent rows blank in that column, a pattern that requires a model to infer "same group as above" rather than "missing data." A related challenge arises in tables with repeating sub-blocks (such as multiple grant cohorts stacked vertically with identical row labels), where a model needs to understand that each block is a self-contained unit rather than a continuation of the one above it.
The five case studies below were chosen to cover the widest range of these failure modes with the least overlap, drawn from SEC filings, academic research, international development documents, and government records across three languages.
Case Study 1: SEC Executive Stock Awards Table
Language: English | Domain: SEC proxy filings | Core challenge: Hierarchical row grouping, superscript footnote markers, sparse grid, multi-level column headers
Source Document
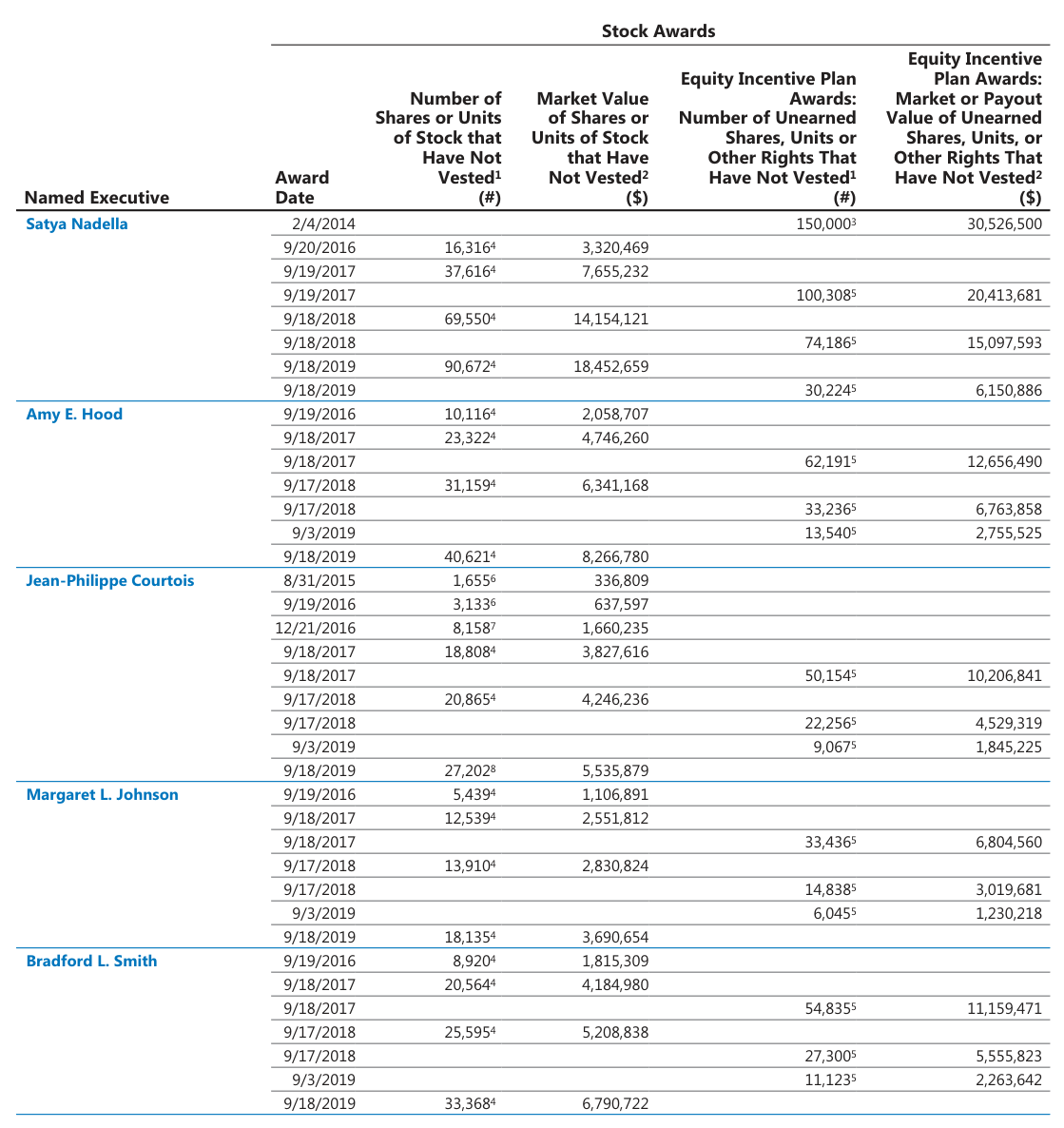
The superscript footnote markers (the small raised numbers attached to share counts like "150,000³" or "16,316⁴") present a second, more subtle challenge. These superscripts reference footnotes elsewhere in the filing, and they need to be preserved exactly as authored because they indicate different vesting conditions, grant types, or calculation methodologies. Models that strip superscripts during OCR cleanup destroy information that's critical for accurate compensation analysis, while models that merge the superscript into the numeric value (reading "150,000³" as "150,0003") produce data that's wrong in ways that are difficult to catch downstream.
Pulse Extraction Output:
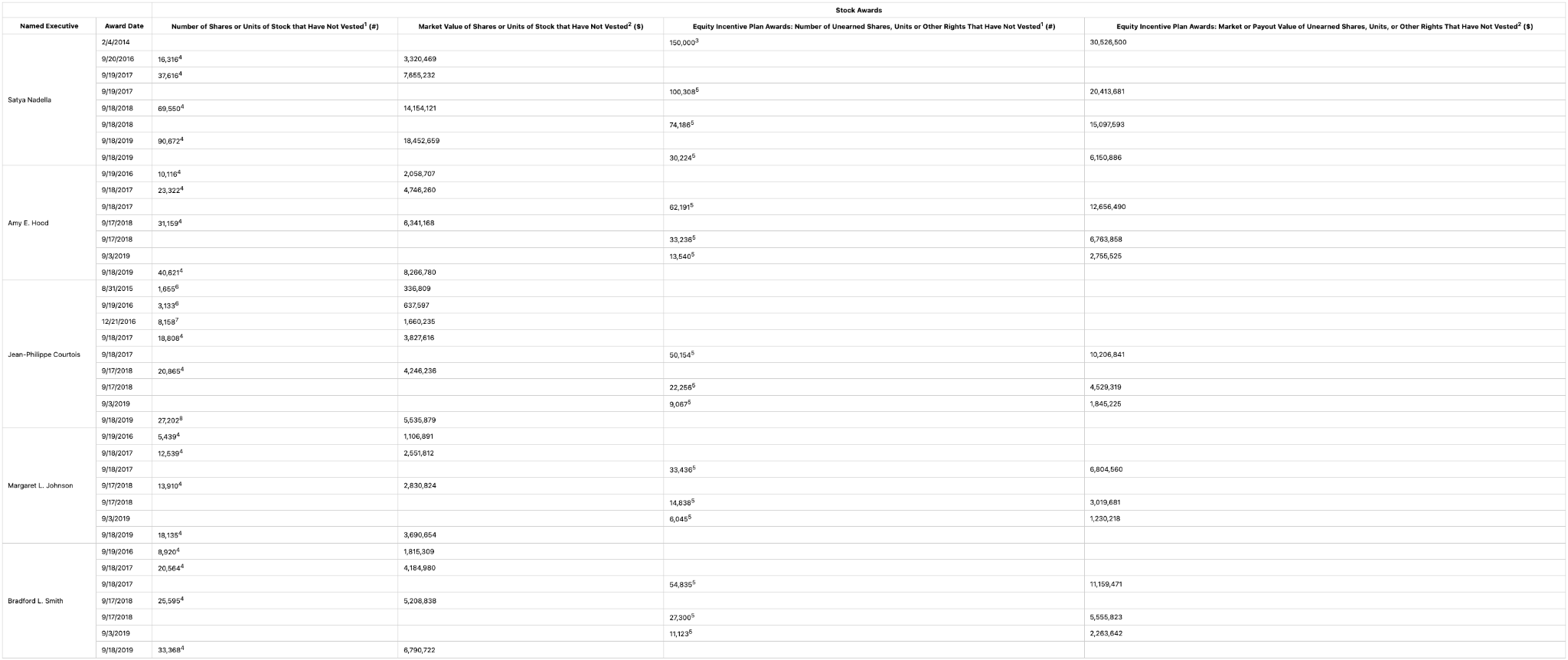
Why this matters: Executive compensation tables in this format are among the most frequently extracted documents in financial services, processed at scale by data providers, compensation consultants, asset managers, and proxy advisory firms. Misassigning an award row to the wrong executive or stripping a footnote marker that distinguishes between grant types can lead to material errors in compensation benchmarking and say-on-pay analysis.
Azure Doc Intelligence Extraction Output:

Why this matters: Azure misreads several executive names and strips the superscript footnote markers entirely, so any downstream compensation analysis loses both the reliable name-based joins to other data sources and the grant-type metadata that distinguishes vesting conditions across awards.
Case Study 2: SEC Proxy Table of Contents
Language: English | Domain: SEC proxy filings | Core challenge: Dot leaders, indentation hierarchy, decorative layout elements, two-panel visual structure
Source Document

The dot leaders are the most common source of extraction errors, as models frequently interpret the dots as cell content, as separators, or as noise to be stripped, rather than recognizing them as a visual bridge between two columns (title and page number). The indentation hierarchy presents another stumbling block: while extracting a flat list of entries is straightforward, preserving the parent-child relationships (recognizing that "Tabulation of Votes" is a sub-item under "Voting," not a top-level section) requires understanding whitespace-based nesting in a structure that has no explicit hierarchy markers.
Pulse Extraction Output:
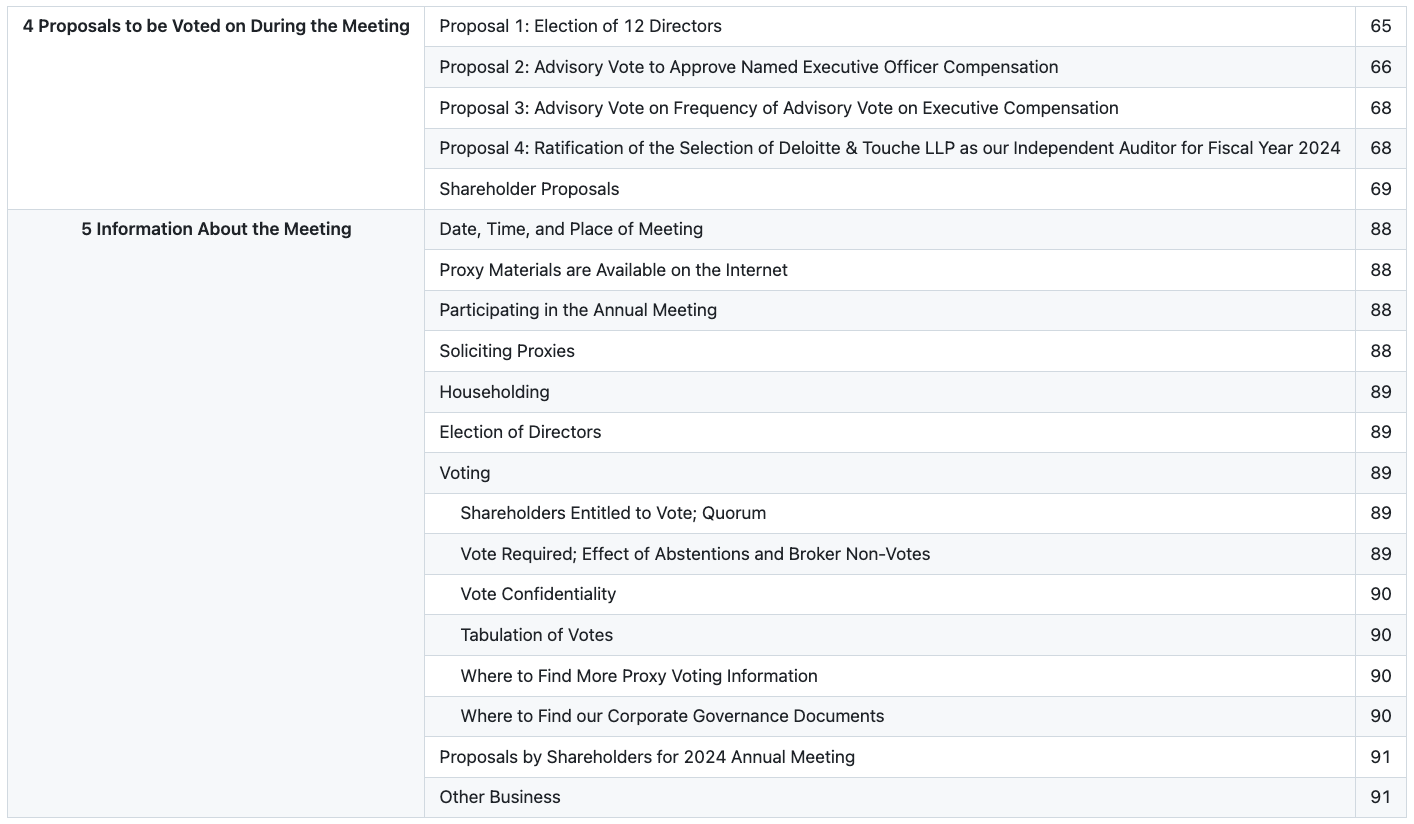
Why this matters: Tables of contents are the structural backbone of long-form documents, and accurate TOC extraction enables automated document navigation, section-level processing, and intelligent chunking for downstream NLP pipelines. Getting the hierarchy wrong means every downstream process that depends on document structure inherits the error.
Reducto Extraction Output:
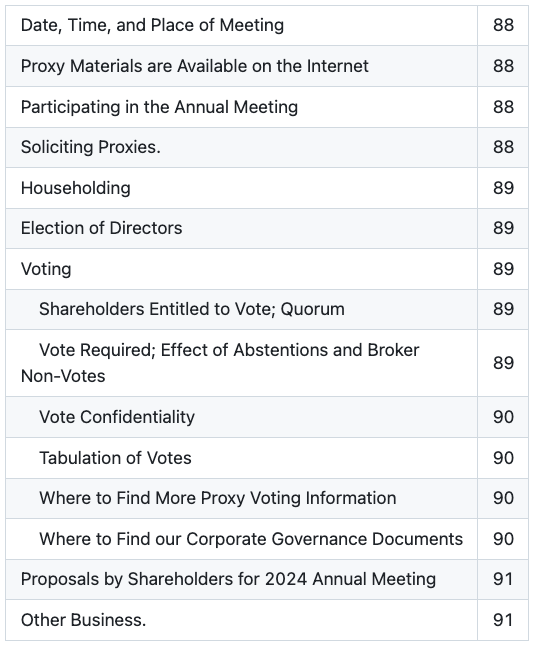
Why this matters: Reducto flattens the two-panel layout into a single uniform list and drops the parent section headers, collapsing the document's top-level navigation and forcing any chunking or retrieval pipeline to re-infer section boundaries from the raw text below.
Case Study 3: Historical English Geographic Table
Language: English (historical) | Domain: Historical geography / cartography | Core challenge: Degraded scan quality, archaic typography, mixed prose and tabular data, complex multi-section layout
Source Document
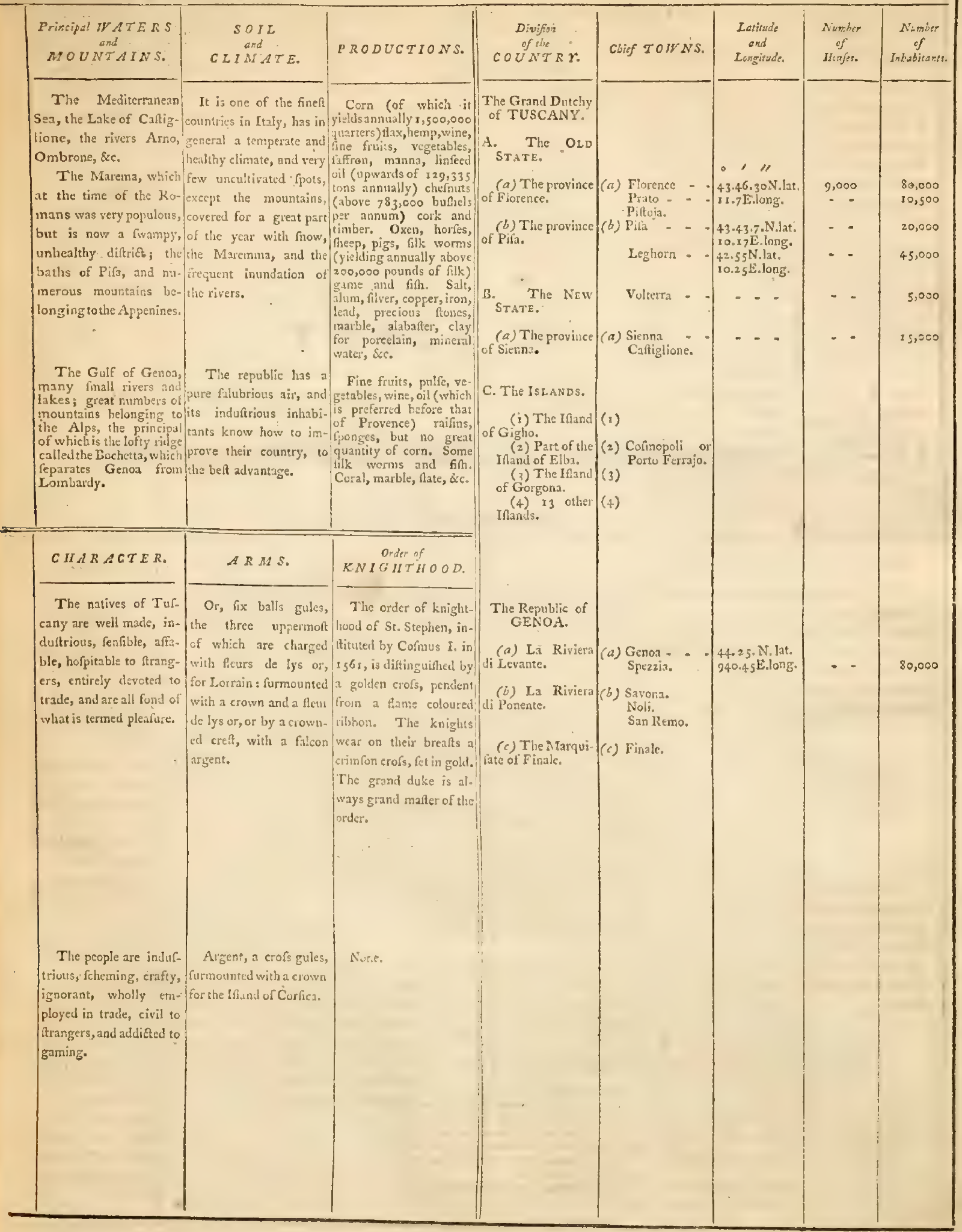
The scan quality introduces noise, uneven character rendering, and inconsistent contrast that challenge OCR at the character level, and the archaic typography (including the long s (ſ), ligatures, and period-specific abbreviations like "Dutchy" and "Caftig-lione") means that even if a model correctly identifies each character, it may not map them to modern Unicode equivalents correctly. The font itself varies between italic and roman faces within the same cell, and ink bleeding across the aged paper creates ambiguous character boundaries that modern OCR systems rarely encounter in production.
Pulse Extraction Output
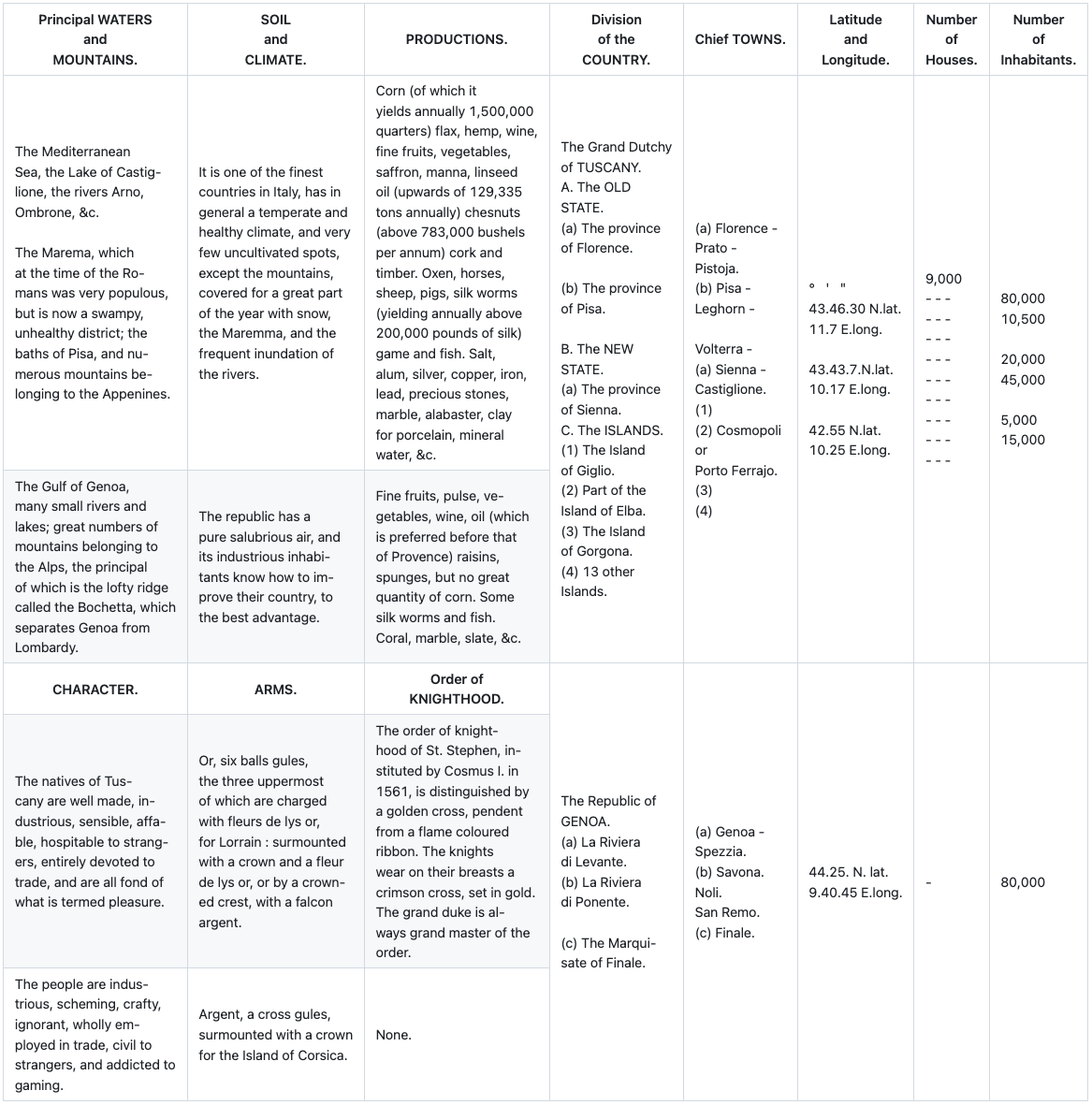
Why this matters: While historical documents aren't the primary use case for most document intelligence buyers, they stress-test the full extraction pipeline in ways that reveal architectural weaknesses. A model that handles degraded scans, archaic typography, and hybrid prose-tabular layouts has demonstrated robustness that transfers directly to production challenges like poor-quality faxes, scanned contracts, and legacy documents that enterprises encounter regularly.
Reducto Extraction Output:
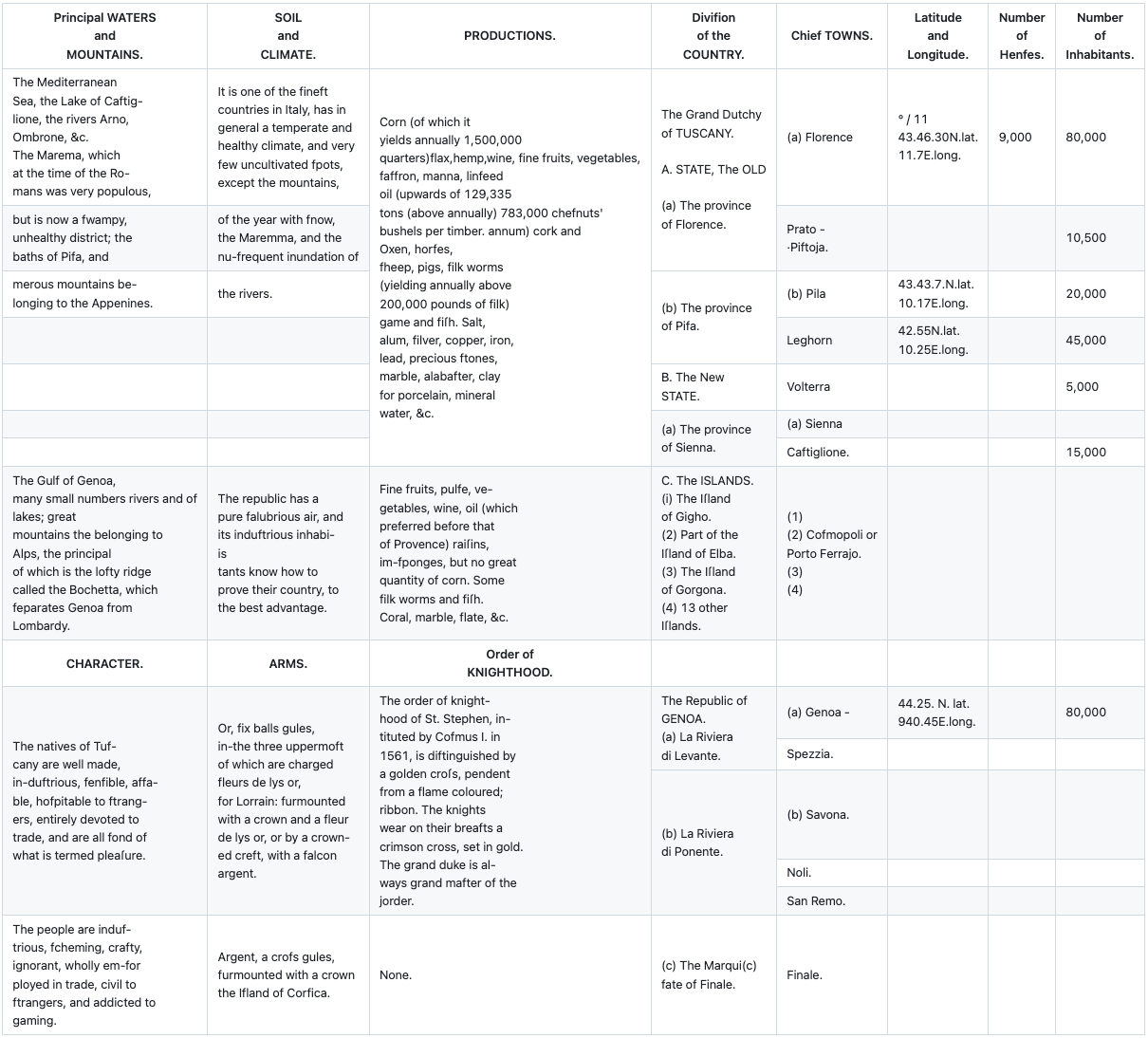
Why this matters: Reducto garbles the archaic typography across most of the prose cells and merges the secondary Character, Arms, and Order of Knighthood schema into the main geographic table, leaving downstream researchers without the structural separation and content fidelity that historical or legacy-document analysis depends on.
Case Study 4: Arabic Project Risk Table
Language: Arabic | Domain: International development / project management | Core challenge: RTL layout, nested sub-tables, merged cells, mixed reading direction
Source Document
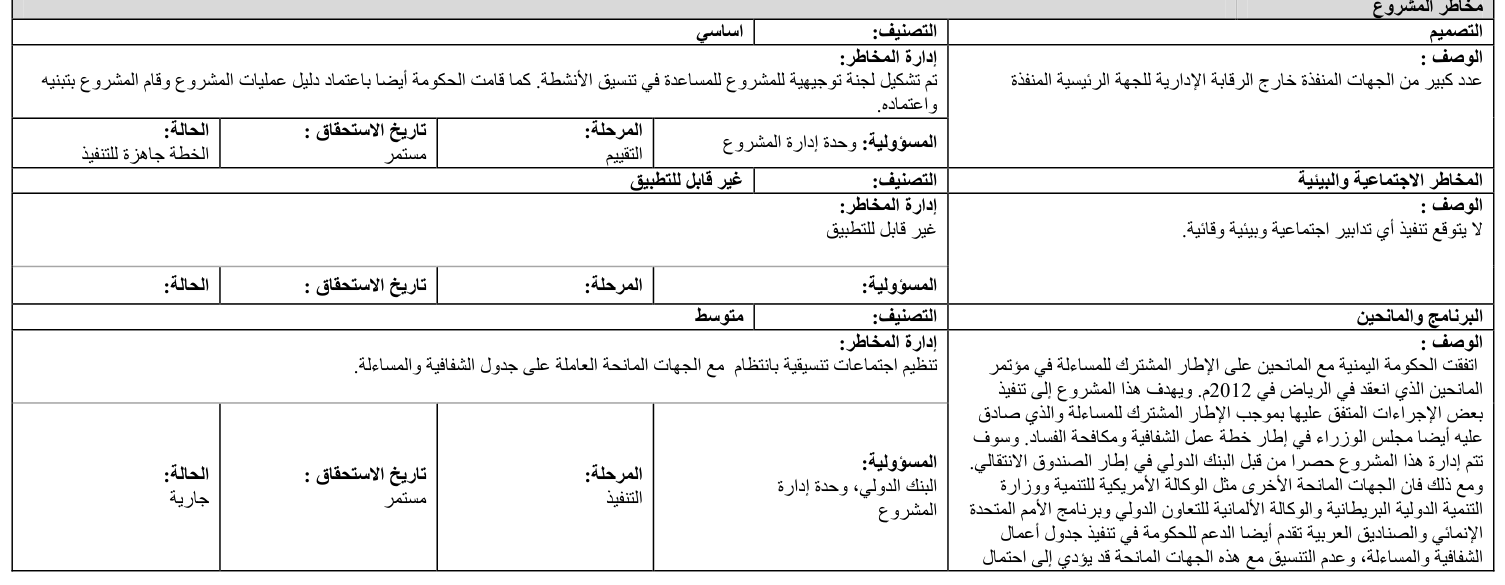
The core extraction challenge is that the table's logical hierarchy doesn't map neatly onto a flat grid. Each risk category occupies a variable number of rows, with the category header spanning the full width, the description text flowing within a merged cell, and the metadata fields appearing in a sub-row with their own internal column structure. A model that attempts to normalize this into a standard row-column format will either lose the hierarchical grouping or misassign metadata fields to the wrong risk category.
Pulse Extraction Output:
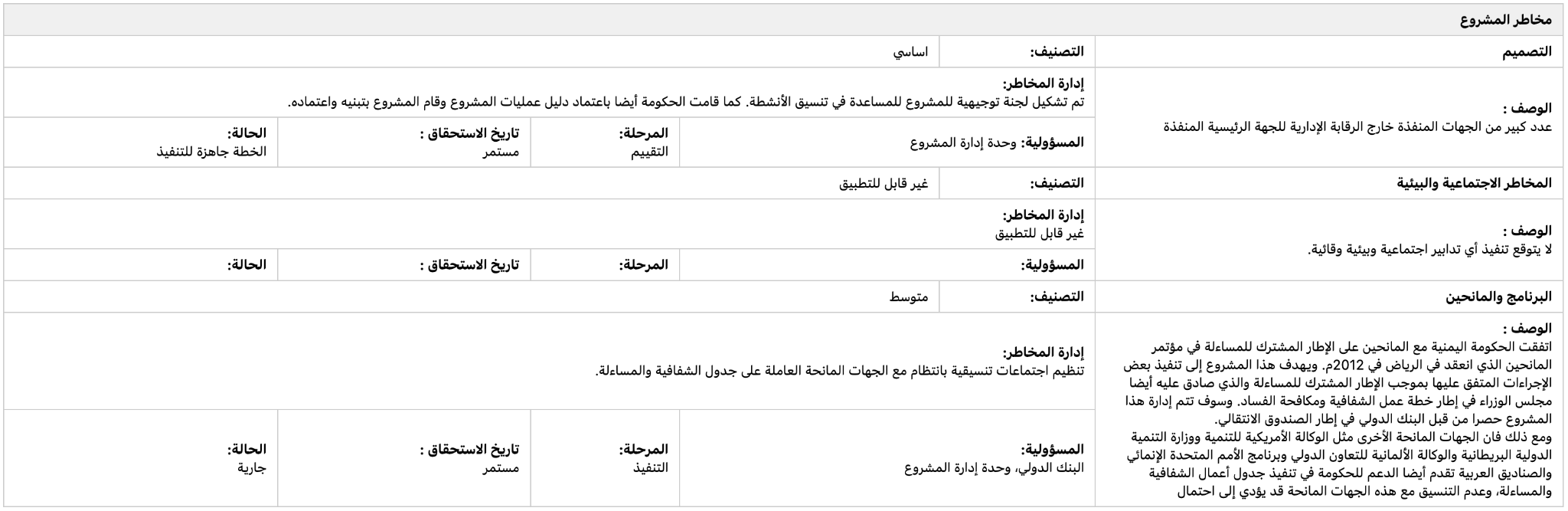
Why this matters: Development finance institutions, multilateral organizations, and consulting firms operating in MENA markets process Arabic-language project documents at scale. Extraction quality on RTL documents is often the difference between automation and manual re-keying.
Gemini Extraction Output:

Why this matters: Gemini preserves the surface cells but loses the parent-child relationship between each risk category header and its metadata sub-row, so responsibility, phase, and status fields can no longer be reliably tied back to the correct risk description in downstream project-tracking or compliance workflows.
Case Study 5: Chinese Consultation Record
Language: Simplified Chinese | Domain: Government / infrastructure planning | Core challenge: CJK character density, variable-length cells, vertical centering, merged first column
Source Document

The CJK text creates unique extraction challenges. Each cell contains dense Chinese characters with no word-level whitespace boundaries, and the text within cells is often vertically centered rather than top-aligned, which means the visual midpoint of the text doesn't correspond to the top of the cell. Models that use vertical position to assign text to rows can easily misalign content when cells of different heights are vertically centered.
Cell content length varies dramatically across columns. The "participants" and "content" columns contain multi-line text blocks with punctuation like Chinese commas used as delimiters within cells, while the "date" column contains compact entries like "2011.9" or "2012.4-5." A model needs to correctly scope each text block to its cell without letting long content in one column bleed into adjacent cells.
Pulse Extraction Output:
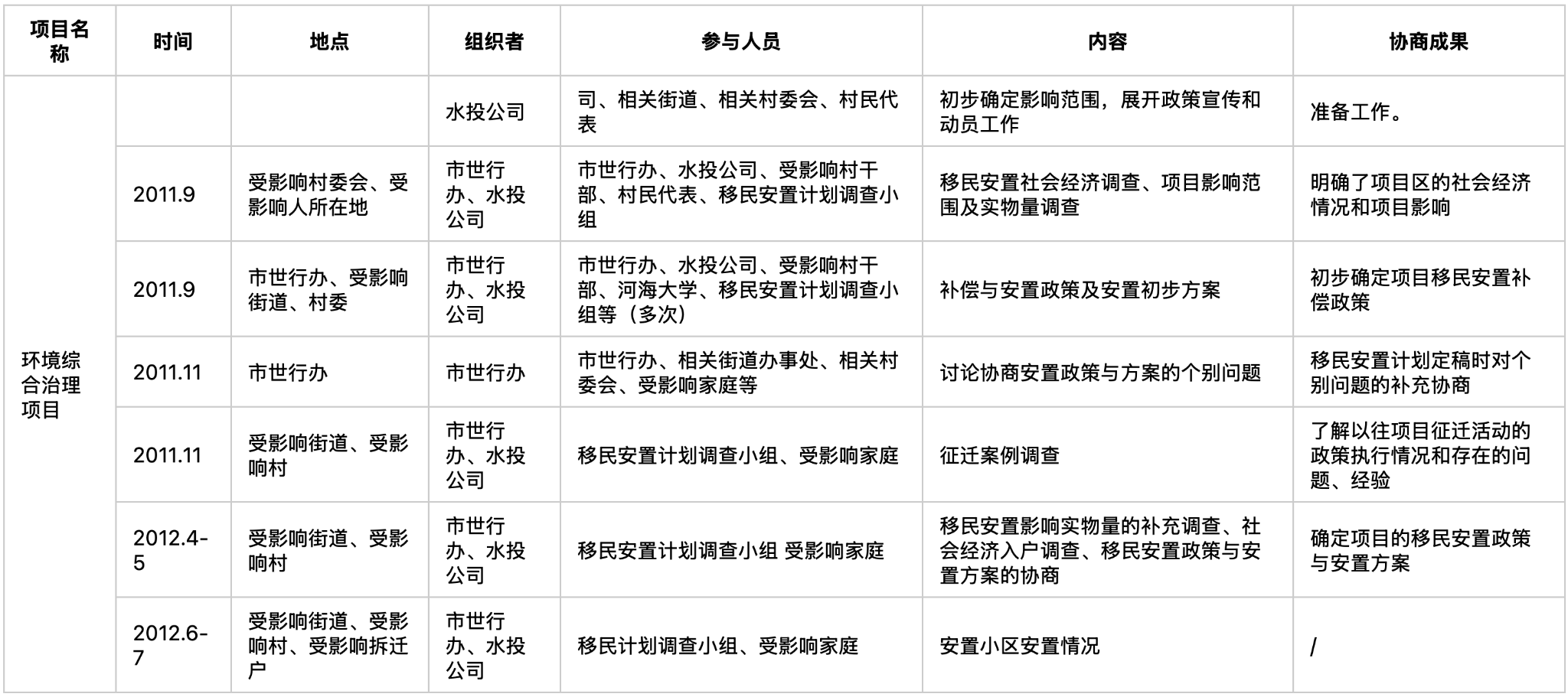
Why this matters: Any organization operating in China or processing Chinese-language regulatory, environmental, or infrastructure documents encounters this format routinely. Government filings, ESG disclosures, and compliance documentation in Chinese frequently use this exact table structure.
Reducto Extraction Output:
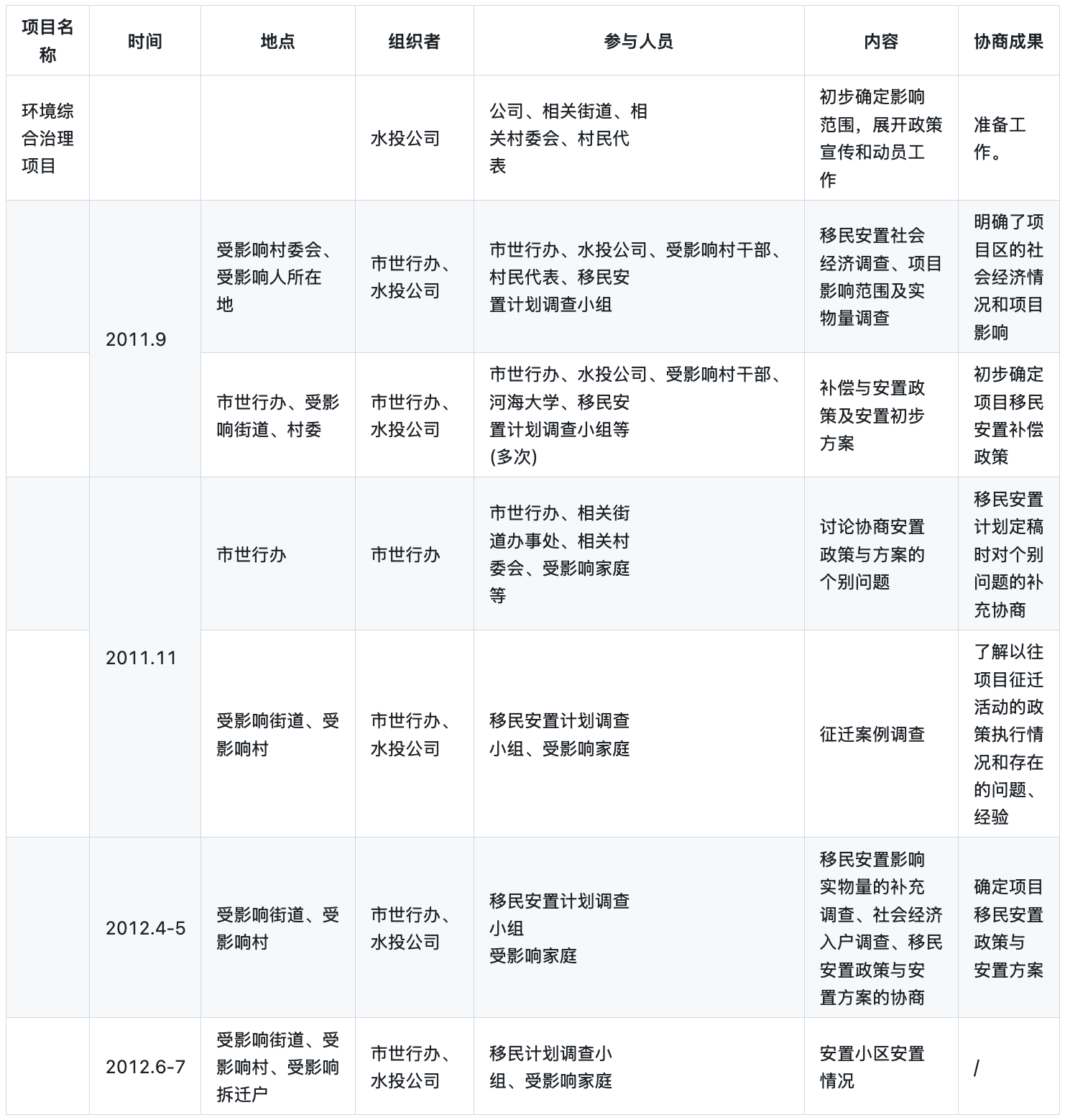
Why this matters: Reducto leaves multiple rows blank in the date column and fragments the long content cells where text crosses each row's vertical centerline, breaking the per-row record integrity that compliance, ESG, and infrastructure-planning analyses rely on when reconciling consultation events back to their dates and outcomes.
Beyond These Five
The five case studies above represent some of the sharpest edge cases in PulseBench-Tab, but the benchmark's coverage extends well beyond them. The full dataset includes SEC proxy filing tables of contents with dot-leader formatting and indentation hierarchies, historical documents with degraded scan quality and archaic typography, Spanish-language policy tables from multilateral organizations where row hierarchy is encoded entirely through visual styling, and Japanese development finance listings where semi-structured text masquerades as tabular data with mixed kanji, katakana, and Latin characters. PulseBench-Tab spans additional document types across these and other languages, ensuring that the benchmark tests extraction robustness across the full range of layouts, scripts, and structural complexity levels that enterprise users actually encounter.
What These Cases Reveal About Architecture
The common thread across all five examples is that table structure is often communicated visually rather than syntactically, and the choice of extraction architecture determines whether that visual structure is preserved or destroyed.
The traditional approach to document extraction runs OCR first to convert the page to text, then applies parsing logic to identify table structures. This pipeline works well on clean, bordered tables where the grid provides unambiguous cell boundaries, but it falls apart on documents like the Russian regression table and the Arabic risk assessment, where structure is communicated through spatial relationships, whitespace, and alignment rather than explicit lines. Vision-language models that operate directly on the page image can leverage spatial reasoning to infer structure from these visual cues, which is the core architectural principle behind Pulse's proprietary VLM.
Conclusion
Table extraction quality is ultimately measured by what works on the documents that matter rather than the ones that are easy, and PulseBench-Tab was built around that principle. The five examples in this post were chosen because they represent the structural challenges that enterprise document processing teams encounter most frequently: nested headers in financial filings, dot-leader hierarchies and indentation structures in proxy filings, degraded historical scans with hybrid prose-tabular layouts, bidirectional layouts in multilingual documents, and dense CJK grids with merged cells and variable alignment
Pulse was purpose-built for exactly these documents, and if the tables in this post look like the documents your team processes, we'd love to show you what Pulse can do with them.

