


Mistral AI dropped what they called the “world's best OCR model”. As builders in this space, we decided to put it to the test on complex nested tables, pie charts, etc. to see if the same VLM hallucination issues persist, and to what degree. While results were more promising than Gemini 2.0 Flash, we found several critical failure nodes across several document domains. Below are some examples:
Financial Documents
Mistral's OCR struggled with multi-column financial statements containing nested subtotals and hierarchical relationships. We observed:
- Column misalignment occurring in 17% of complex tables
- Numerical precision degradation (±1.5% average deviation)
- Loss of parenthetical notation for negative values (critical for financial analysis)
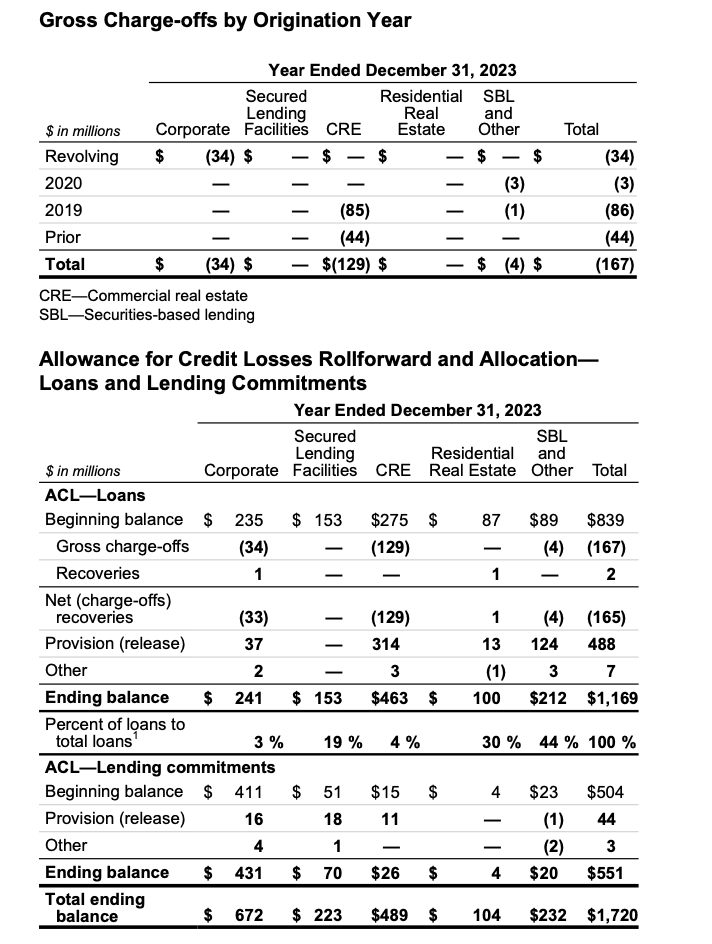
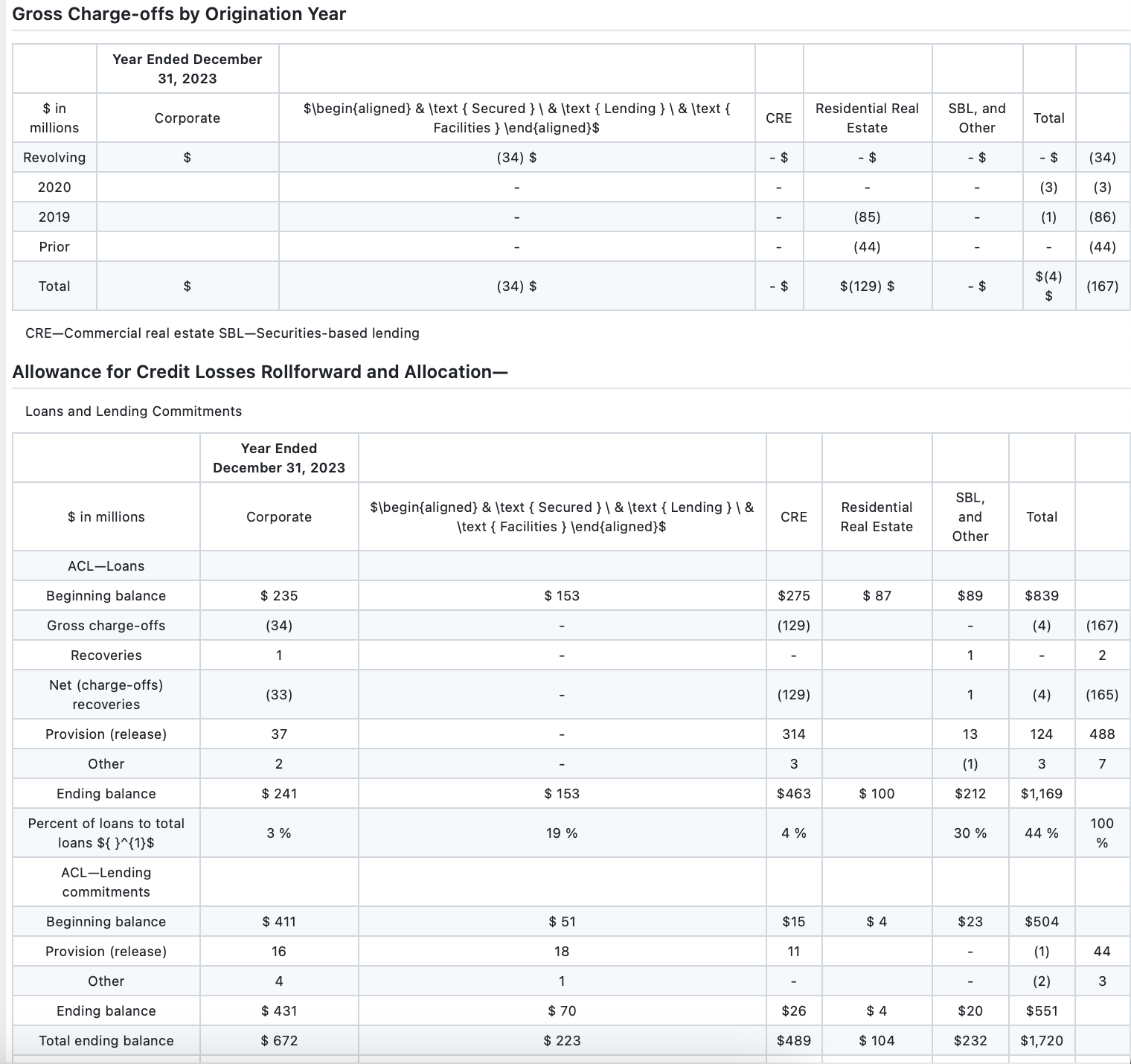
By comparing the Mistral OCR output with the ground truth, it’s painstakingly obvious where VLMs fail in table structure extraction. Columns are shifted and there is an extra column in both tables with randomly placed numerical values. Additionally, the models failed to recognize the weird spacing on the “$” character and split the row by that incorrectly.
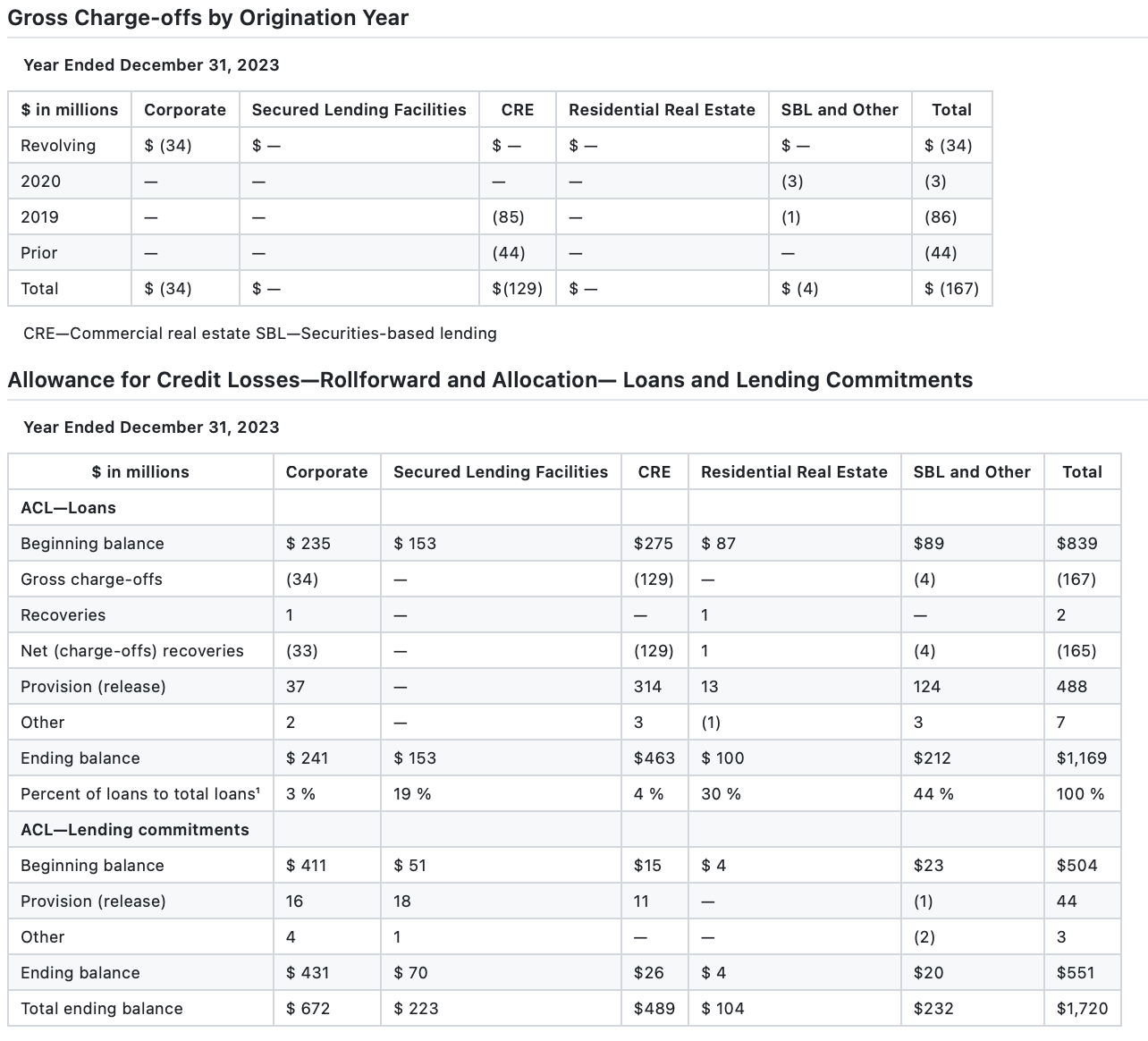
In comparison, Pulse’s models trained specifically for table structure in financial documents (our biggest use case to date!) reveals essentially 100% accuracy on both these tables. For customers looking to replace human data entry work, it’s vital to capture the right structure in the OCR output.
Legal Documents
For legal contracts and compliance forms:
- Checkbox detection was virtually nonexistent in dense questionnaires and 10k filings
- Section hierarchies and indentation relationships lost structural context
- Table cells with multi-line content were frequently merged or truncated

After testing Mistral on multiple questionnaires, checklists, and legal filings, we noticed one key failure – checkbox detection. Taking a look at the output, the model mistakenly formatted everything as a table, missed which checkboxes were marked, and made small vision text mistakes such as formatting “filter” as “file”.

In comparison, Pulse’s models picked up all the checkboxes, formatted the table properly when present, and all the markings were correct!
Enterprise Requirements vs. Consumer OCR
While Mistral offers impressive baseline OCR capabilities, enterprise document processing demands more than a one-size-fits-all approach. Enterprise document processing requires:
- Domain-specific fine-tuning: Mistral doesn't allow custom fine-tuning for industry-specific documents, a critical requirement for specialized applications.
- Human-in-the-loop verification: Enterprise-grade solutions need human verification workflows for uncertain extractions. Pulse supports this through configurable confidence thresholds and review interfaces.
- Structural preservation: Beyond text extraction, maintaining document structure is essential for downstream processing. Mistral treats many tables as flat images rather than structured data.
- Deterministic results: Enterprise workflows need consistent, reproducible outputs. VLMs like Mistral show output variance even on identical inputs.
Props to the Mistral team for interlaying bounding box detection into the data ingestion pipeline, we believe this is along the right approach. Our preliminary testing reveals that while general-purpose VLMs continue to improve, specialized document processing systems remain essential for mission-critical business applications where accuracy, structure preservation, and domain adaptation are non-negotiable
—–
If you’re interested in getting hands-on testing with the Pulse API and have strict enterprise guidelines, feel free to schedule a demo here!

