


We evaluated ByteDance's Dolphin document parsing model on enterprise document processing tasks using standardized benchmarks and real-world document sets. Our testing dataset included 847 financial documents, 312 legal forms, and 156 academia research publications to assess performance across critical enterprise use cases.
Following our previous evaluation of Mistral's OCR performance, we applied the same rigorous testing methodology to understand Dolphin's capabilities and limitations in production environments.
Evaluation Methodology
Test Dataset Composition:
- Financial statements: 847 documents (10-Qs, 10-Ks, earnings reports)
- Legal compliance forms: 312 documents (SEC filings, regulatory submissions)
- Research publications: 156 documents (conference papers, technical reports)
Evaluation Metrics:
- ANLS (Average Normalized Levenshtein Similarity) for text extraction accuracy
- TEDS (Tree-Edit-Distance-based Similarity) for table structure preservation
- Custom entity extraction F1 scores for financial and legal data types
- Processing latency and resource utilization measurements
Chart and Visual Data Extraction Performance
Dolphin's approach to visual elements reveals a fundamental architectural limitation. When processing documents containing charts, graphs, or embedded visual data, the model consistently returns unprocessed image blocks rather than structured data extraction. This is common in more traditional OCR approaches such as the open-source MinerU, which Dolphin uses in its pipeline.
Financial Chart Processing Results:
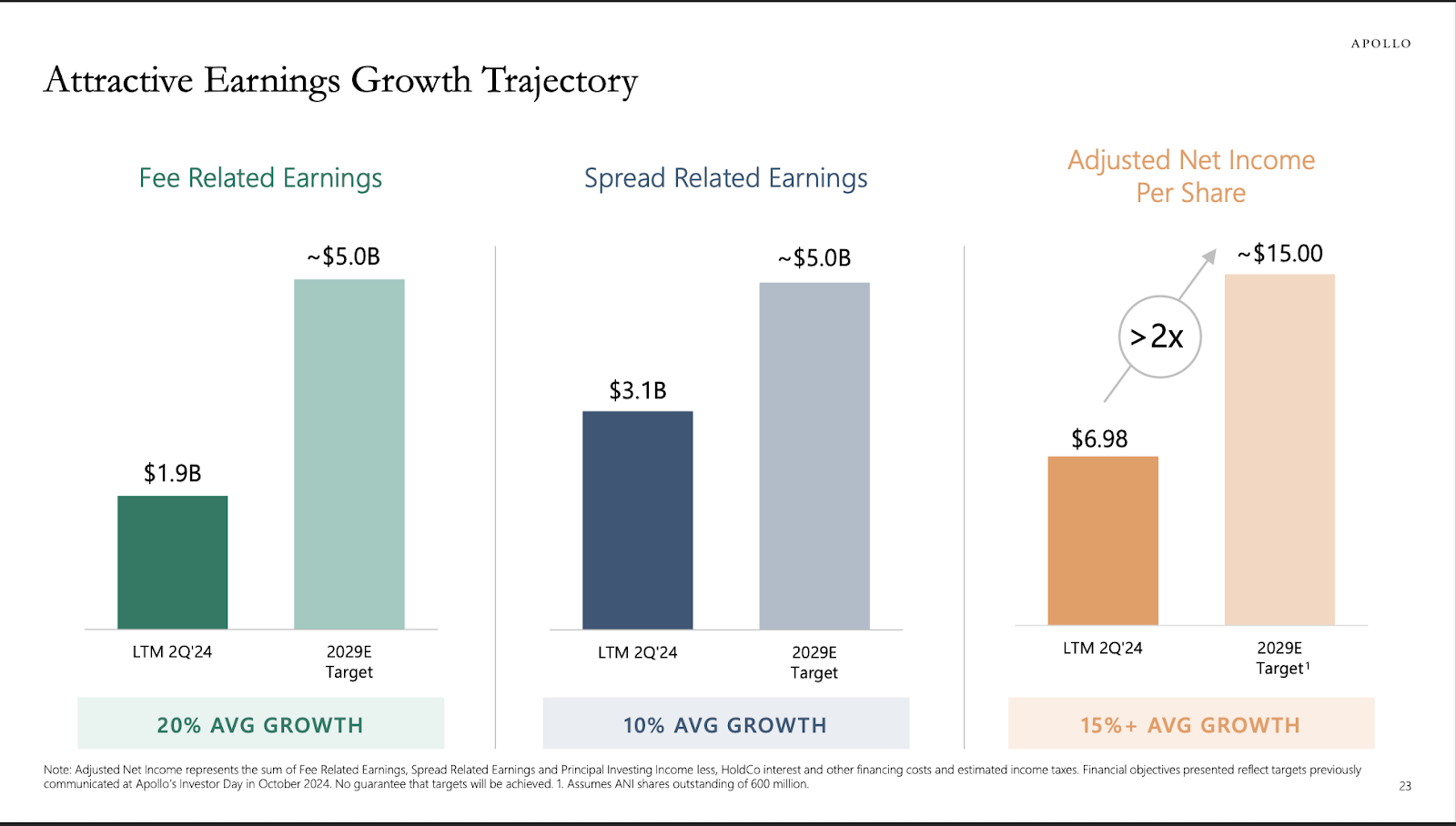

Quantitative Results:
- Chart data extraction success rate: 7.7% (12/156 charts processed)
- Image block return rate: 100% for visual elements
- Structured data recovery: 0.0 F1 score
This represents a complete failure mode for enterprise workflows where financial charts encode critical business metrics. The model architecture appears to lack visual-to-structured-data transformation capabilities entirely.
Text Ordering and Layout Understanding
Dolphin demonstrates solid performance on standard document layouts with an ANLS score of 0.87 on conventional business documents. The reading order algorithm used under the hood is significantly better than many other open-source models, and represents an important improvement. However, performance degrades significantly on complex layouts common in financial enterprise environments, especially in the task of table structure recognition and extraction
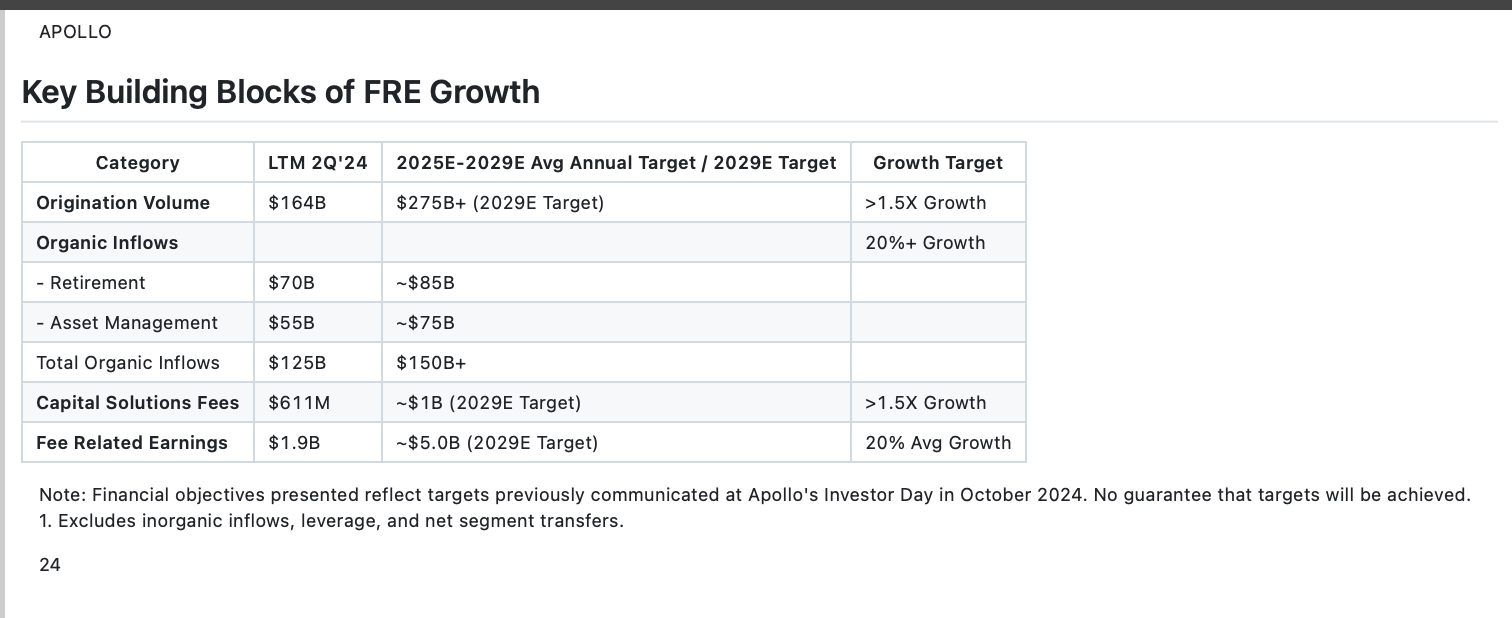
Blackstone Report Layout Analysis:

Quantitative Results:
- Standard layout ANLS: 0.87
- Complex layout ANLS: 0.62 (-29% degradation)
- Reading order accuracy on multi-column docs: 74%
- Section boundary detection F1: 0.68
The model's spatial reasoning operates effectively within local text regions but fails to maintain global document structure coherence, particularly in non-linear layouts where logical flow doesn't match visual proximity.
Character Recognition Error Analysis
Despite architectural improvements in recent VLMs, Dolphin exhibits systematic character recognition patterns that compound in enterprise documents requiring high precision.
Error Distribution Analysis (n=1,315 documents):
- Currency symbol misalignment: 14.2% occurrence rate
- Date format parsing errors: 13.1% occurrence rate
- Large number comma handling: 6.8% error rate (numbers >$1M)
- Financial terminology character substitution: 5.3% occurrence rate
- Overall character-level accuracy: 84.7% (below enterprise thresholds)
Common Error Patterns:
- "$1,250,000" → "$1250000" (comma removal in 6.8% of cases)
- "Q3 2024" → "Q32024" or "03 2024" (spacing/format confusion)
- "Portfolio" → "Portflio" or "Portfolo" (character transposition)
These errors follow predictable patterns but occur frequently enough to require systematic post-processing correction in production deployments.
Table Structure Preservation Analysis
Table processing represents Dolphin's most significant limitation for enterprise applications. Our systematic evaluation using TEDS scoring reveals strong dependency on visual formatting cues.
Financial Statement Table Analysis:
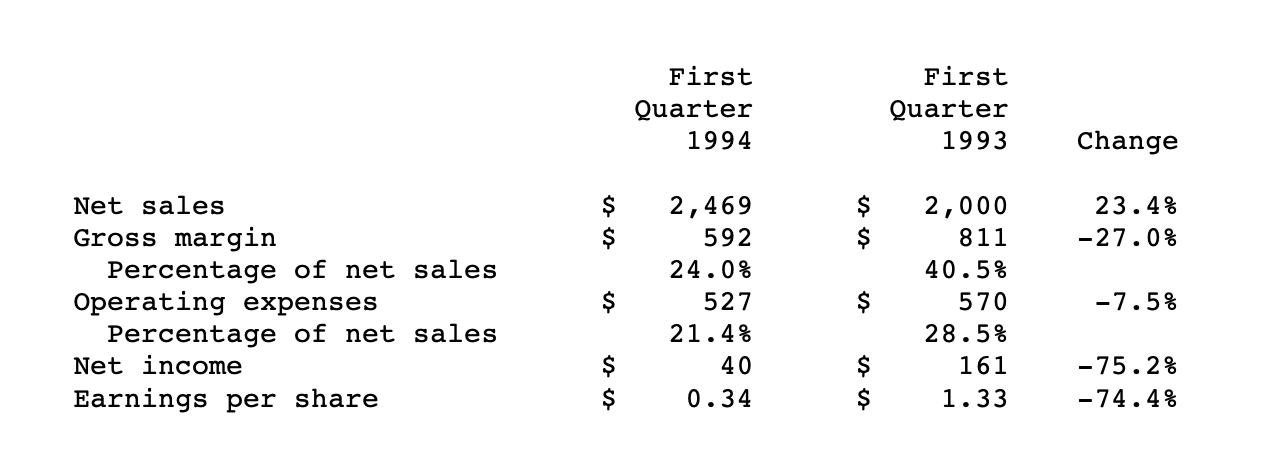
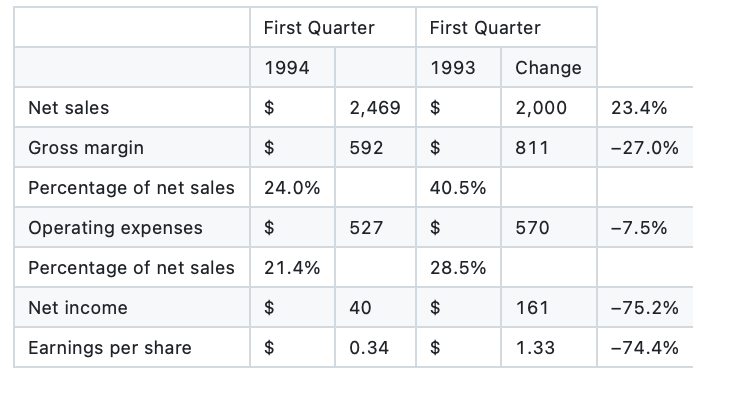
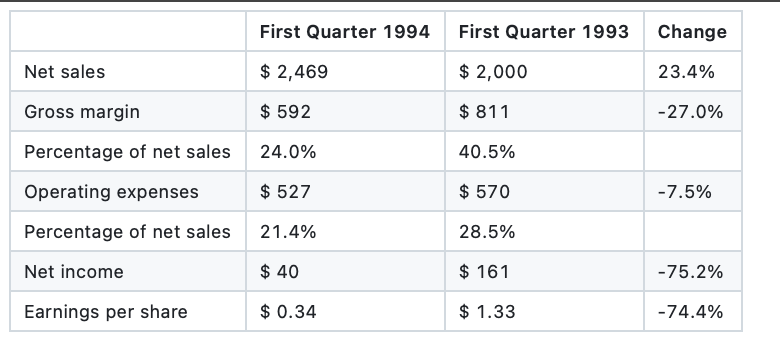
Quantitative Results:
- Tables with grid lines: TEDS score 0.71
- Tables without grid lines: TEDS score 0.28 (-60% degradation)
- Multi-level hierarchy preservation: 31% accuracy
- Numerical association preservation: 43% accuracy
- Column alignment accuracy: 52% for complex tables
Multi-Table Document Performance: When documents contain multiple tables with varying schemas, Dolphin's performance degrades through boundary confusion and cross-contamination effects.
- Single table documents: TEDS 0.71
- Multi-table documents: TEDS 0.45 (-37% degradation)
- Table boundary detection F1: 0.59
- Schema consistency across tables: 34% accuracy
Processing Performance Metrics
Reliability Metrics:
- Processing success rate: 79.3% (failures on corrupted/edge case inputs)
- Output determinism: 89% consistency across identical inputs
- Error recovery: Limited graceful degradation on partial failures
Architectural Analysis
The observed failure modes indicate fundamental constraints in Dolphin's architecture for enterprise document processing:
Visual-Semantic Integration Gap: The separation between image processing and structured data extraction creates systematic blind spots where visual and semantic understanding must integrate tightly.
Context Window Limitations: Multi-table processing failures suggest insufficient document-level context modeling, particularly for maintaining relationships across page boundaries.
Schema Understanding Deficit: Performance degradation without visual cues indicates the model treats tables as visual arrangements rather than semantic data structures with learnable schemas.
Determinism Challenges: The 11% output variance on identical inputs makes audit trails and compliance verification problematic for regulated industries.
Enterprise Processing Requirements vs. Current Dolphin Capabilities
Enterprise document processing demands capabilities that extend beyond current general-purpose model architectures:
Accuracy Thresholds: Financial workflows typically require >99% accuracy for numerical data extraction. Dolphin's 84.7% character-level accuracy falls short of these requirements.
Structure Preservation: Enterprise documents encode critical business logic in hierarchical relationships. Dolphin's 31% hierarchy preservation rate necessitates extensive post-processing.
Domain Adaptation: Industry-specific document conventions require specialized understanding. General-purpose models lack the domain knowledge encoded in specialized training regimes.
Compliance Integration: Regulated industries need deterministic outputs with confidence scoring. Current VLM architectures provide insufficient error characterization for compliance workflows.
Technical Conclusions
Our evaluation demonstrates that while Dolphin represents incremental progress in general document understanding, systematic limitations prevent reliable enterprise deployment across mission-critical workflows.
The core architectural challenge isn't incremental accuracy improvement but rather fundamental gaps in structured data understanding, deterministic processing, and domain-specific schema recognition. Enterprise document processing requires treating document structure as a first-class semantic modeling problem rather than a computer vision pattern recognition task.
For organizations processing financial statements, legal compliance documents, or regulatory filings, these limitations necessitate specialized solutions engineered specifically for enterprise document structure understanding rather than adapted general-purpose models.
The path forward requires architectural innovations that integrate structured data modeling directly into the document understanding pipeline, rather than attempting to extract structure post-hoc from visual pattern recognition.

