


Most financial services firms have invested heavily in document AI over the past few years. The promise is compelling: automate the tedious work of extracting data from CIMs, financial statements, and research reports so analysts can focus on higher-value analysis.
But there's a gap between the demo and reality. The next generation of document AI works well on clean, simple documents. The issue is financial documents are neither clean nor simple. They combine complex table structures, dense numerical data, and visual elements in ways that push the current models beyond their designed capabilities.
At Pulse, we’ve been testing document AI systems across thousands of financial documents to understand where the technology breaks down. We tested the latest language models, open source solutions, and enterprise platforms. The pattern is consistent: systems that achieve 90%+ accuracy on standard text drop to 70-80% accuracy on the structured financial data that drives analytical decisions.
The gap isn't about character recognition. It's about understanding the structural relationships that make financial documents meaningful.
The Table Structure Problem
Financial documents are built around complex table relationships that standard OCR systems simply don't understand. Unlike simple invoices or contracts, financial statements use nested hierarchies where the structure itself carries meaning.
Take a typical quarterly earnings breakdown. You might have revenue split by geography, then by business unit, then by product line, with subtotals and percentages at each level. Traditional systems process each cell independently, completely losing the relationships that make the data meaningful.
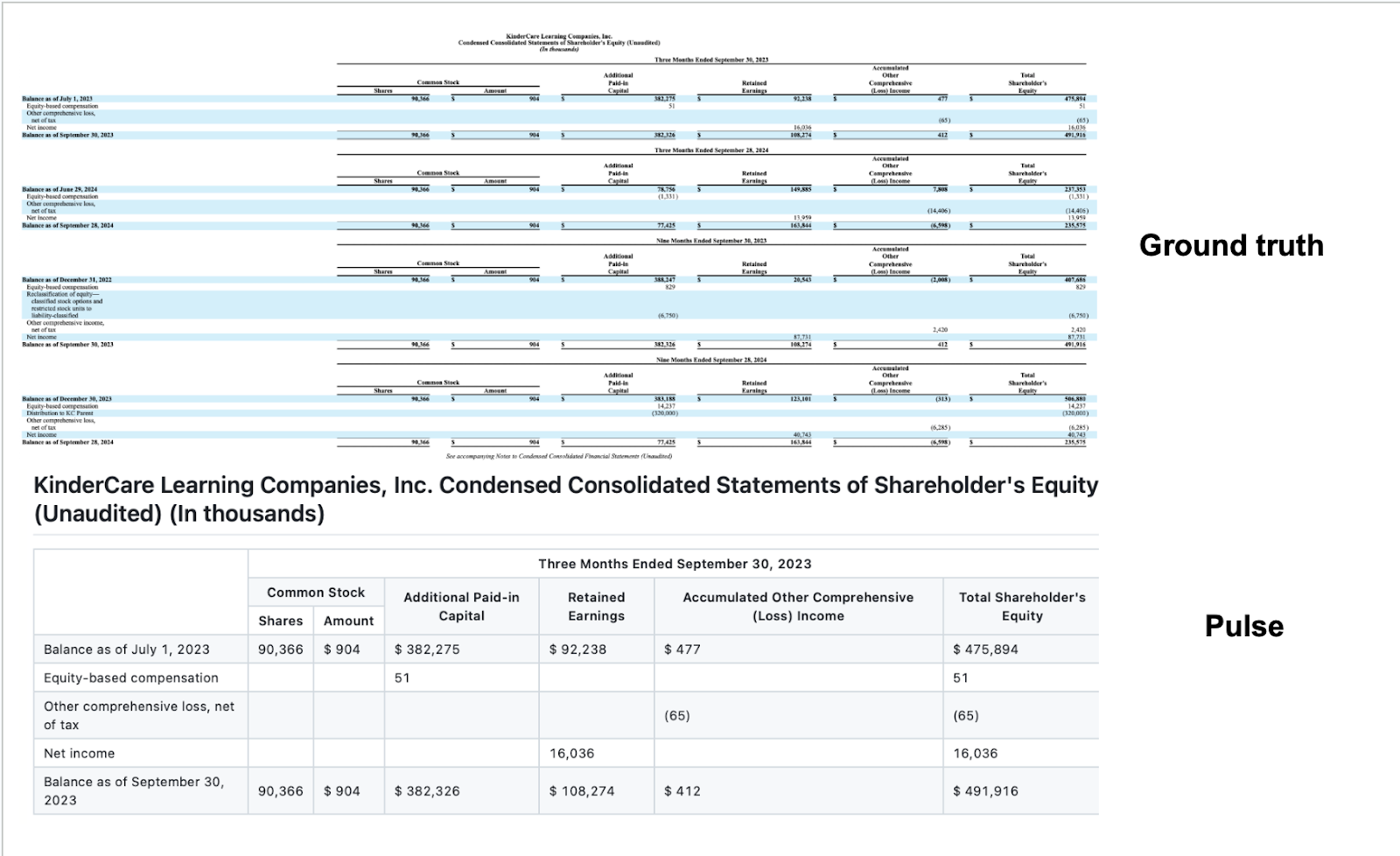
We've seen systems correctly extract every individual number from a complex P&L while completely scrambling which numbers belong to which categories. The raw data is perfect, but the structure that makes it useful disappears entirely.
This isn't a character recognition problem. It's an architectural limitation of systems designed for simpler document types. Pulse’s approach to this is via extremely granular bounding box detection and a suite of heuristic algorithms that determine when to merge cells.
Chart and Graph Blindness
Modern financial documents rely heavily on visual elements to communicate key insights. Revenue trends, market share breakdowns, geographic distributions, growth trajectories. These aren't decorative. They often contain the most important analytical insights in the entire document.
Traditional document AI either ignores charts completely or tries to extract text from legends and labels, missing the actual data relationships entirely.
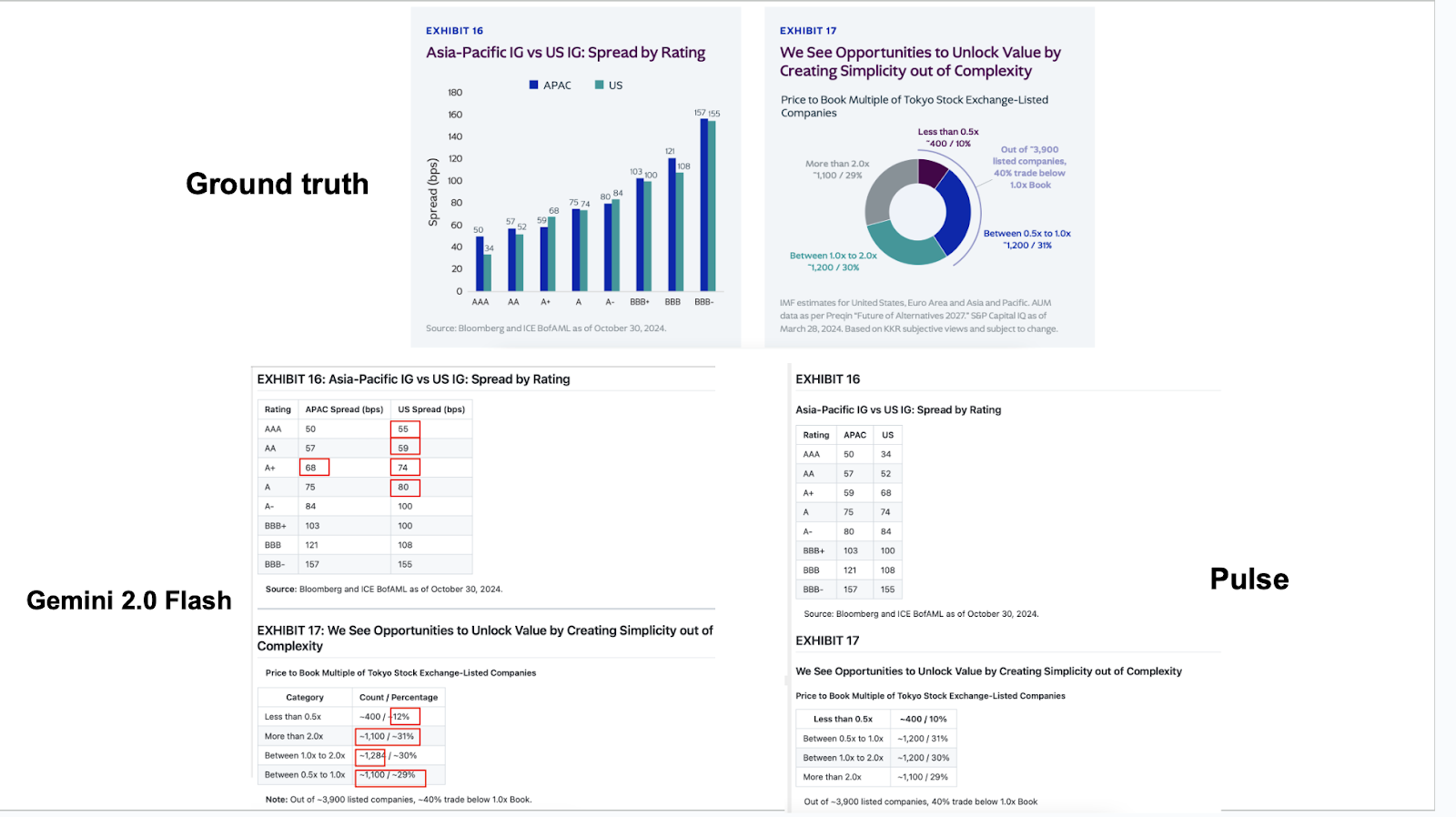
We tested this systematically across hundreds of CIMs and financial presentations. Chart-based insights, which often represent 40-60% of the analytical value in these documents, simply disappear during processing. Teams end up manually recreating analyses that should have been automated.
The Precision Tax
Financial analysis operates with precision requirements that don't exist in other industries. A small OCR error in a legal contract might require manual correction. The same error in financial data can cascade through interconnected calculations, creating systematic analytical distortions.
Currency and decimal handling represents a particular failure mode. Systems that reliably process $1,234.56 in invoices start making errors when the same format appears in dense financial tables with varying fonts and formatting. We've observed systematic decimal shifting where $1,234.56 becomes $12,345.6 or currency markers disappear entirely.
Percentage processing creates similar cascading problems. Growth rates, margins, and ownership percentages appear in dozens of different formats across financial documents, and traditional systems handle them inconsistently.
The downstream impact compounds. A 1% error in extracting a key financial metric can shift valuation models by 10-20%. When you're processing hundreds of documents for portfolio analysis or market research, these errors accumulate into systematic analytical bias.
The Real Estate Challenge
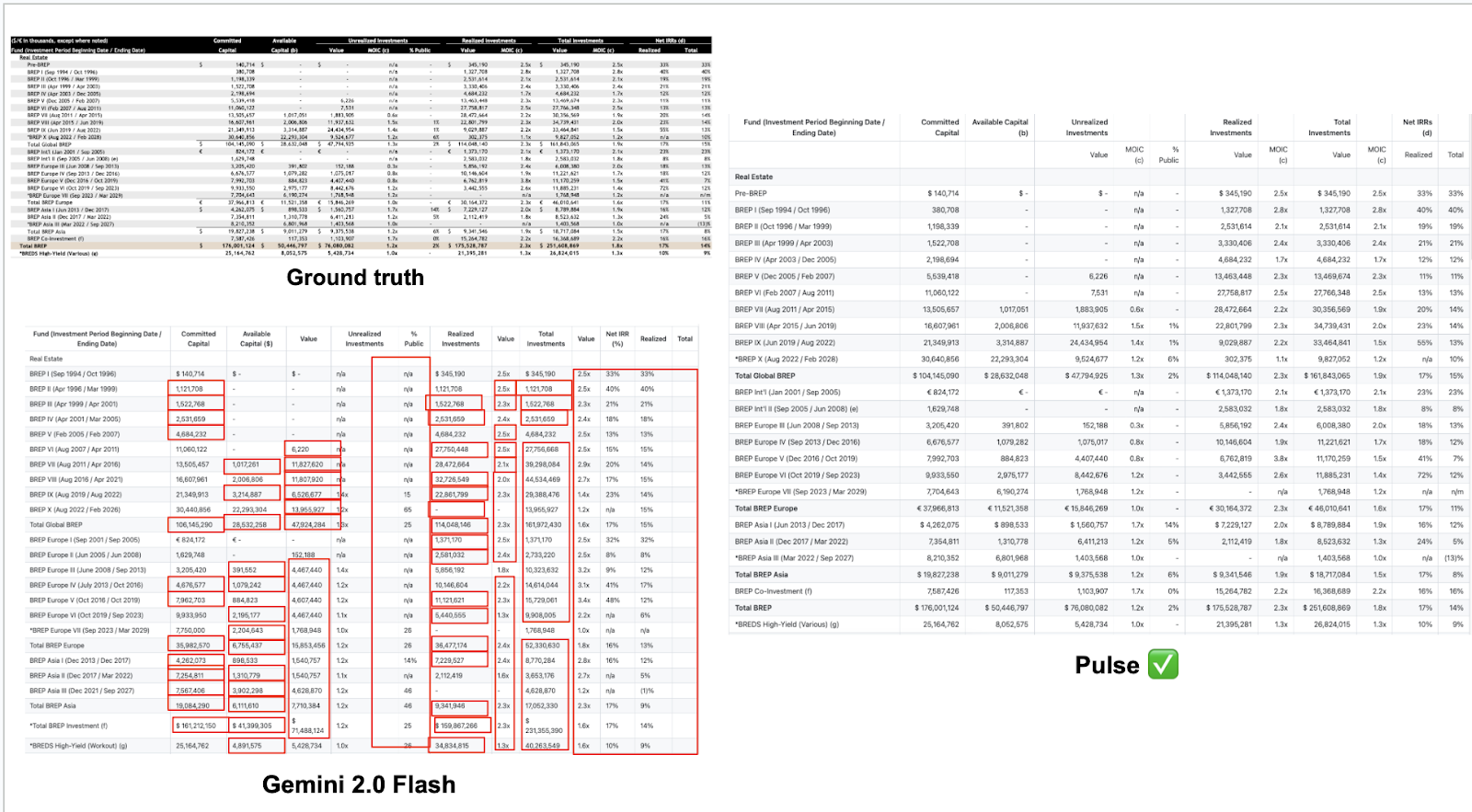
In our experience dealing with thousands of different document layouts, real estate financial documents represent the absolute limit of document complexity. Rent rolls, operating statements, and property-level financial reports, to be specific. These combine dense numerical data with complex formatting in ways that break every traditional processing system we've tested.
A typical institutional property rent roll contains 20+ interconnected columns: tenant information, lease terms, base rent, escalations, percentage rent, expense recoveries, renewal probabilities. Traditional AI processes these as independent data points, completely losing the economic relationships that define property performance.
We've worked with several REITs on their document processing workflows. The consistent pattern we observe before they try Pulse is that traditional systems extract most of the raw data correctly but lose the analytical context.
The Enterprise Workaround Problem
Most financial services firms have developed elaborate workarounds for these limitations rather than solving them directly. The result is document processing workflows that are more complex and time-consuming than manual processes, while still requiring extensive manual verification.
Hybrid processing chains where documents get run through multiple systems, with humans filling gaps and correcting errors. The automation savings get consumed by coordination overhead.
Extensive verification protocols where analysts manually check all extracted financial data before using it in models. This eliminates the time savings from automation while adding verification work that didn't exist in manual processes.
Selective automation where firms only automate the simplest document types, manually processing anything complex. This creates systematic bottlenecks where the documents that take longest to process manually are the same ones that can't be automated.

Financial services firms are investing heavily in document AI based on demonstrations using simple examples. But real enterprise workflows involve complex document types where current technology doesn't work reliably.
Internal tool development projects that assume reliable document extraction are building on unstable foundations. Firms focusing on semantic search systems can't accurately process CIMs due to errors in the ingestion step. Analytics platforms built from the ground up routinely miss chart-based insights. The firms that acknowledge these limitations and build purpose-built solutions will have systematic advantages over those that continue layering workarounds onto inadequate technology.
The financial services industry needs document processing technology built specifically for the structural complexity and precision requirements of financial documents. Current solutions work well for standard business documents but fail systematically on the complex financial structures that drive investment and analytical decisions.

This isn't about replacing human analysts. It's about giving them reliable automation for the document processing work that currently consumes 30-40% of their time while producing unreliable results.
—
We're working with several of the largest financial institutions to solve document processing for complex financial documents. Want to see how purpose-built systems compare to your current solutions? We can run direct comparisons on your document types.

