


When people talk about document AI challenges, they usually mention PDFs or scanned forms. But our research team has found that XLSX files present some of the most difficult parsing problems we encounter at Pulse. The reason is structural ambiguity at scale.
Unlike a PDF where layout is fixed, spreadsheets contain layered complexity: merged cells that span arbitrary regions, multi-tab workbooks where context lives across sheets, and formatting that sometimes carries meaning and sometimes doesn't. A cell's value might depend on formulas referencing other tabs, headers might be split across rows, and data regions blend with decorative elements.
Standard approaches to spreadsheet extraction treat each cell as an independent token or serialize the grid row-by-row, which works for simple tables but breaks down rapidly when you're dealing with real enterprise workbooks.

The token efficiency problem
Standard approaches to spreadsheet extraction create significant overhead. A 50-tab financial model serialized naively can exceed context windows before you've even started processing. Merged cells create coordinate ambiguity-does a value belong to row 3 or rows 3-5? Cross-sheet references lose their graph structure when flattened, and whitespace or formatting cells pollute the token stream with non-semantic data.
This inefficiency has cascading effects. When your VLM is spending tokens on empty cells and formatting artifacts, it has less capacity for the actual structural relationships that define what the data means. Layout segmentation struggles because the signal-to-noise ratio is poor, and table boundary detection degrades when the model can't distinguish between data regions and decorative elements at scale.
What our research team found
Our research team developed and implemented a spreadsheet encoder that compresses XLSX structural information while preserving the relationships that matter for extraction. The encoder maintains cell adjacency, merge spans, and cross-sheet linkage in a representation optimized for the Pulse VLMs, rather than treating spreadsheets as linear sequences or naive grid serializations.
The approach improves token efficiency substantially, allowing us to process larger workbooks within context limits without sacrificing the geometric and hierarchical relationships that define spreadsheet structure. We're seeing measurable improvements in our layout segmentation classifier's ability to detect table boundaries, and the system more reliably distinguishes between actual data regions versus headers, footers, and formatting artifacts that shouldn't be extracted as content.
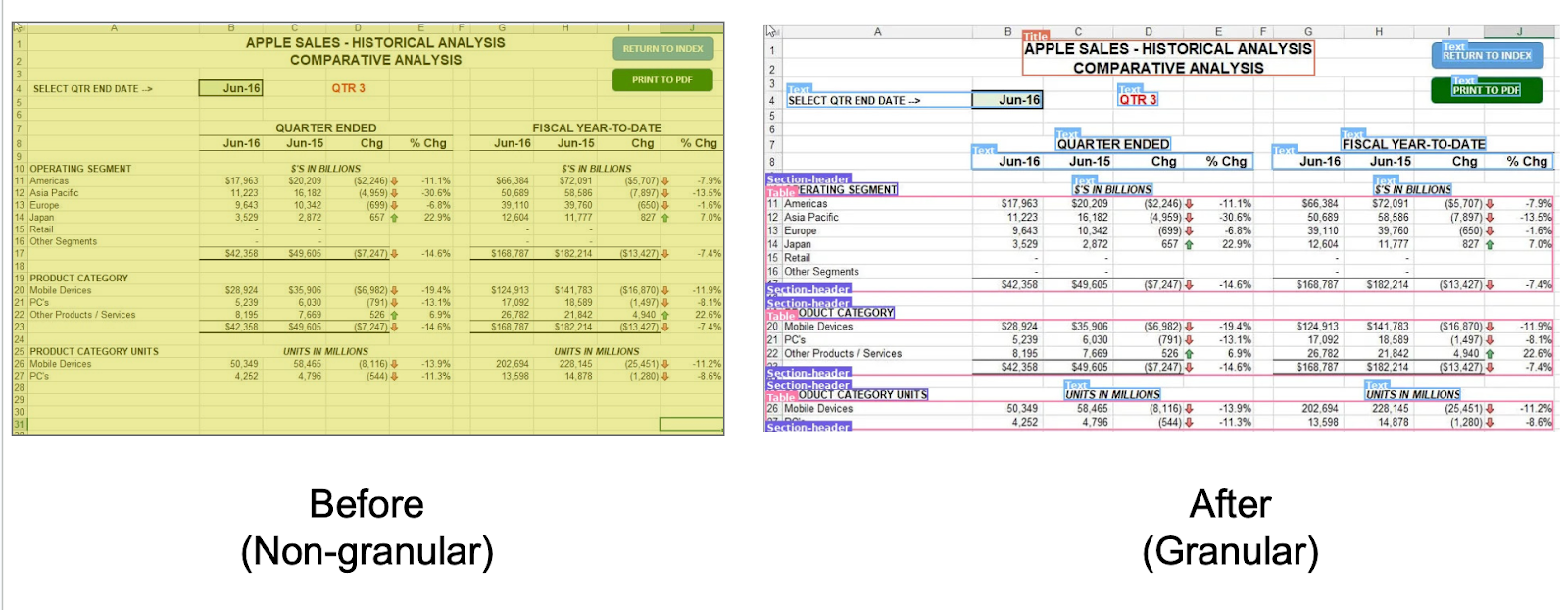
Why this matters for document extraction
The geometry problem we described in our previous writing on tables applies even more acutely to spreadsheets. A misaligned column in a rent roll or a formula reference that points to the wrong tab produces outputs that look correct but are structurally wrong, and these are the errors that propagate silently through downstream systems. Spreadsheets are not a side case for document extraction-they are the native format for financial models, inventory systems, and operational reports in virtually every industry where structure and relationships define meaning.
Our encoder addresses this by treating spreadsheet structure as a first-class object throughout the pipeline. When Pulse processes a multi-tab P&L, it understands which cells are headers, which are data, and how they relate, even when the formatting is inconsistent or the layout spans dozens of tabs. Cell coordinates, merge boundaries, and cross-sheet relationships are preserved rather than flattened away, which means the extracted data retains the structural fidelity required for reliable downstream use.
Preview access for complex XLSX processing
We're offering early access to teams working with large, structurally complex XLSX files. If your extraction workflows involve multi-tab workbooks, irregular layouts, or scenarios where preserving cross-sheet relationships is critical, reach out to us at hello@trypulse.ai.

