


The pattern across banking, insurance, and energy is the same, in that the highest-value documents are also the messiest. In banking, that means loan tapes with hundreds of asset-level columns, credit memos with embedded financial spreads, term sheets with covenant grids, and CIM packets supporting M&A processes, while in insurance it means ACORD submission forms with supplemental schedules, treaty slips and broker placement files, loss runs spanning a decade of claims activity, and policy schedules covering thousands of locations, and in energy it means well files, division orders, JIBs, geotechnical reports, and the regulatory filings that sit on top of all of it.
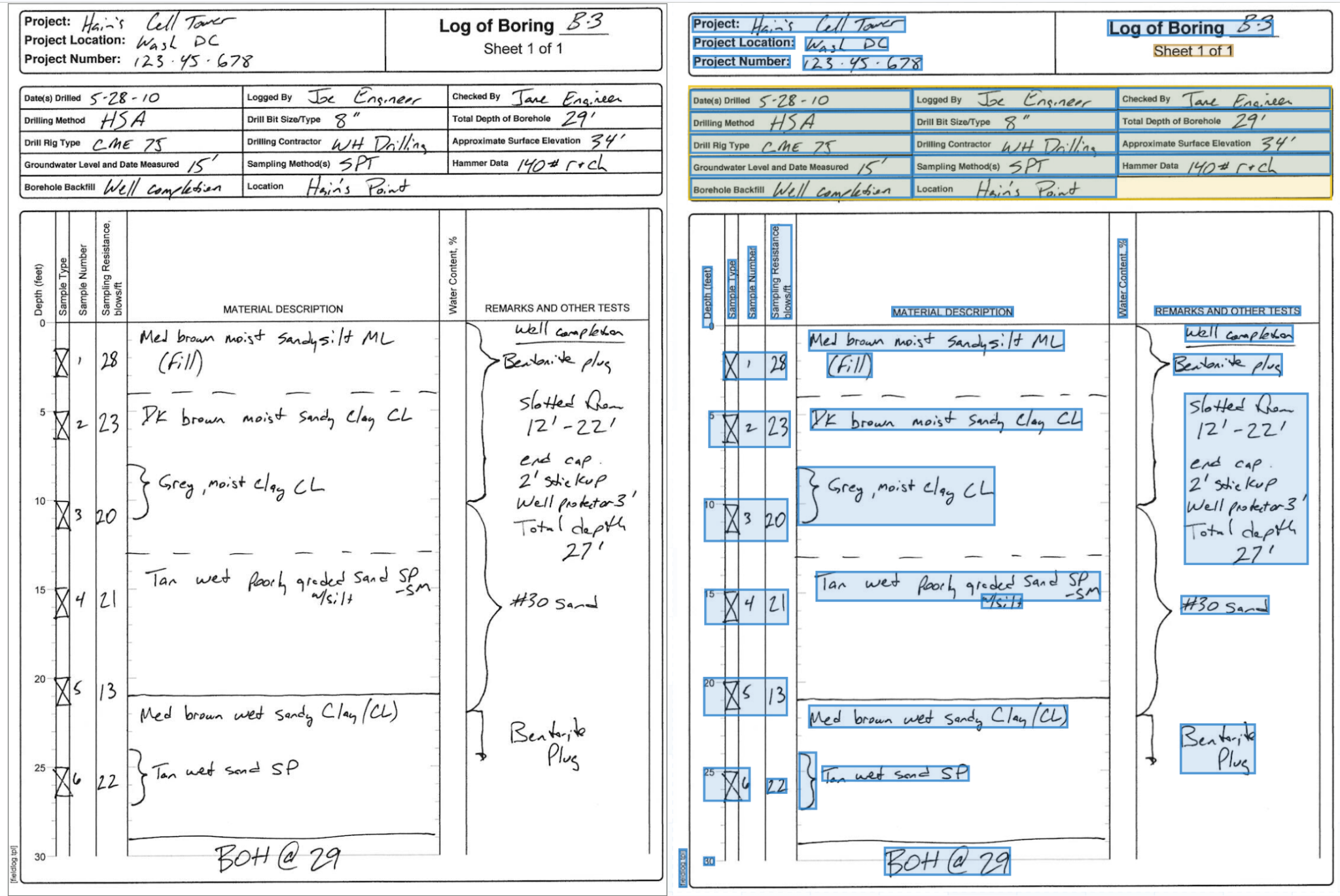
The document above is a real example of what regulated workflows actually look like at the source. It is a Log of Boring, a geotechnical field record produced during a subsurface investigation at a cell tower site, and every field on the page was filled out by hand by an engineer standing next to a drill rig. The header captures the project name, location, drilling method, rig type, drill bit size, sampling method, hammer data, total depth, groundwater level, and the names of the engineers who logged and checked the work, while the body of the form records sample numbers, sampling resistance in blows per foot, and material descriptions for each interval of the borehole, alongside well completion notes spanning bentonite plugs, slotted screen intervals, end caps, stickup, and well protector specifications.
A document like this carries enormous downstream weight, because the lithology and blow counts feed foundation design calculations, the groundwater level drives dewatering and seismic considerations, the well completion details govern environmental monitoring obligations, and the engineer's signature establishes professional liability. None of it is structured for a database, none of it is consistent across drilling contractors, and none of it is legible to any general-purpose document tool, because the structure is not on the page, it lives in the institutional knowledge of the geotechnical engineers who have always read these logs.
The structure problem in regulated documents
Documents like this boring log were authored for human readers operating inside a specific institutional context rather than for downstream automation, which means they assume the reader knows the conventions, recognizes the abbreviations, and understands what a blank field implies. A geotechnical engineer reading "Med brown moist sandy silt ML (Fill)" immediately parses that as a Unified Soil Classification System designation indicating low-plasticity silt of artificial fill origin, while a generic document model sees a string of characters with no semantic anchor. The same problem repeats across every regulated industry, where the most important documents encode decades of professional convention into shorthand, abbreviations, and visual layouts that only domain experts can decode.
This is why general-purpose document tools fail on the documents that matter most. Loan tapes are not just spreadsheets, they are spreadsheets where column meaning depends on the originator and the asset class, while treaty slips are not just contracts, they are layered placements where the order of the layers determines who pays first, and division orders are not just tables, they are decimal-interest calculations where eight digits of precision determine real money. The structure is implicit, contextual, and domain-specific, and it does not survive the transition to a tool that was trained on web pages and academic papers.
What Pulse returns
When Pulse processes a boring log like the one shown above, the output is not a transcription, it is a structured representation of the document with every field grounded back to its location on the source page. Header metadata becomes a project record, the body of the log becomes a depth-indexed sequence of soil intervals with classifications and sampling resistance preserved at the field level, and the well completion column becomes its own structured set of intervals with material types and depth ranges. Every extracted field carries a bounding box pointing back to the exact location on the source document, which is what makes the output usable in regulated environments. When a regulator, a client, or an internal QA reviewer wants to verify that the blow count at fifteen feet really was twenty-one, the citation back to the original log is one click away.
Why this matters beyond geotechnical
The boring log is one example, but the principle generalizes across every regulated industry Pulse serves. A loan tape gets extracted as a loan tape with covenant fields, asset-level performance metrics, and originator-specific column conventions preserved, while a treaty slip gets extracted as a treaty slip with layer attachments, cession percentages, and reinsurer panels intact, and a division order gets extracted as a division order with owner decimals carried to the eighth place and tract descriptions linked to county and survey identifiers. In every case, the extraction respects the conventions of the document type rather than forcing the page through a generic table parser, and in every case, the output is grounded back to the source for full auditability.
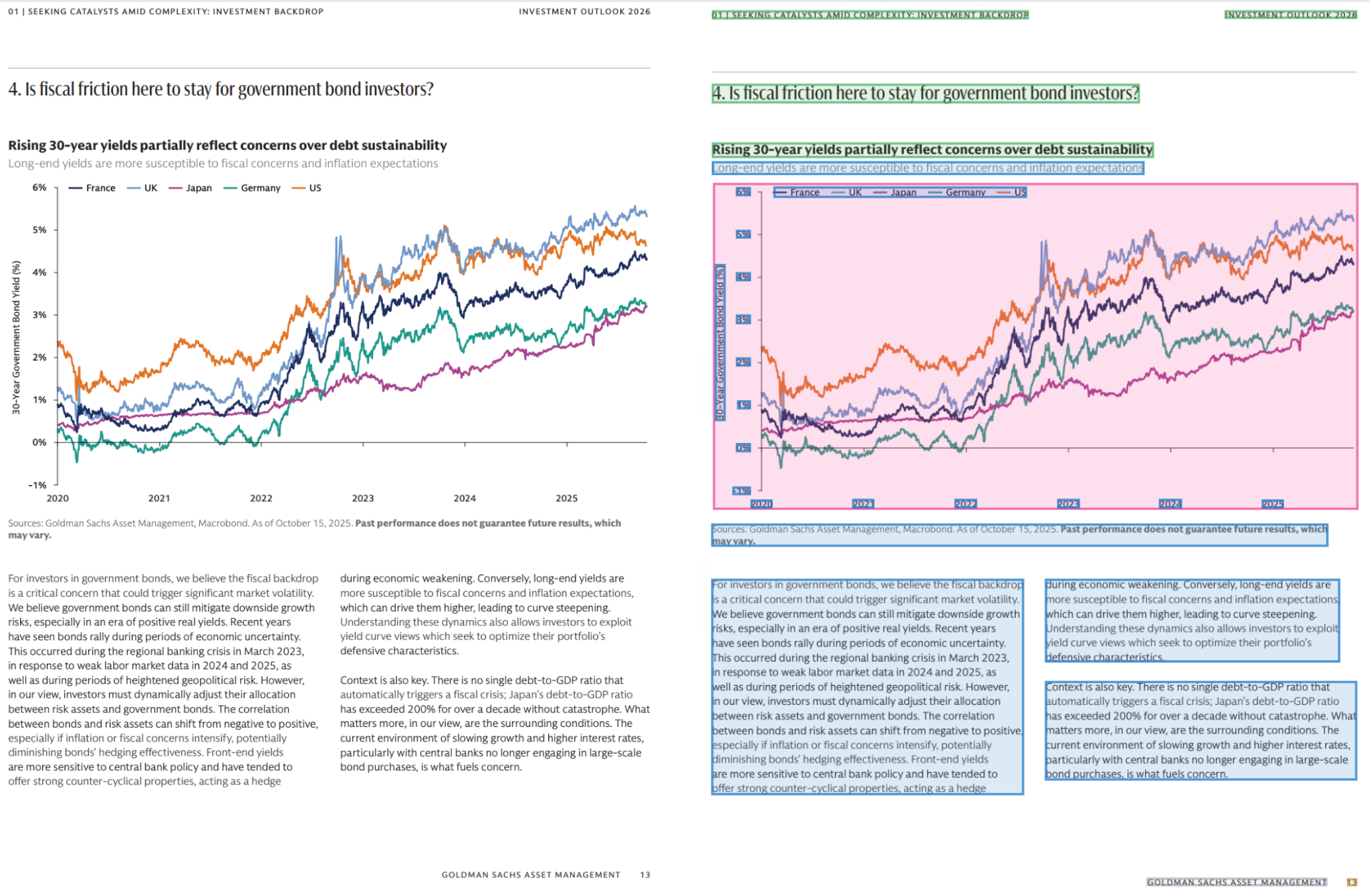
The same capability that handles a handwritten field log also handles polished institutional documents like the Goldman Sachs Investment Outlook page shown above, where charts, captions, footnotes, and body copy all carry meaning that has to be preserved together. The contrast is the point: one document was filled out with a pen at a drill site, the other was laid out by a design team at a global asset manager, and the structural extraction has to work the same way on both, because the documents that bottleneck the most important workflows in the enterprise span exactly that range of formats and authorship.
The highest-value documents in the enterprise will keep being authored by humans for humans, because the people who fill them out are operating inside conventions that exist for good reasons. The work of Pulse is to make those documents legible to the rest of the stack without losing what makes them trustworthy in the first place, which is why Fortune 50 banks, global insurers, and the largest financial data providers in the world run Pulse in production rather than retrofitting general-purpose models for document work.

