


Mistral released OCR 4 - the obvious question on our end working in the space was a narrow but vital one: how does it handle tables? Table extraction is one of the toughest parts of document understanding, so we ran OCR 4 through the full PulseBench-Tab document set the same day it shipped.
PulseBench-Tab is our open benchmark for multilingual table extraction, built with academic contributions from S&P Global and spanning 1,820 tables across nine languages. It scores models on T-LAG, a metric designed to reward structurally faithful extraction rather than surface-level text overlap, which is why it tends to expose the gap between models that read a page and models that actually reconstruct the grid underneath it.
Here is where OCR 4 lands against the rest of the field:
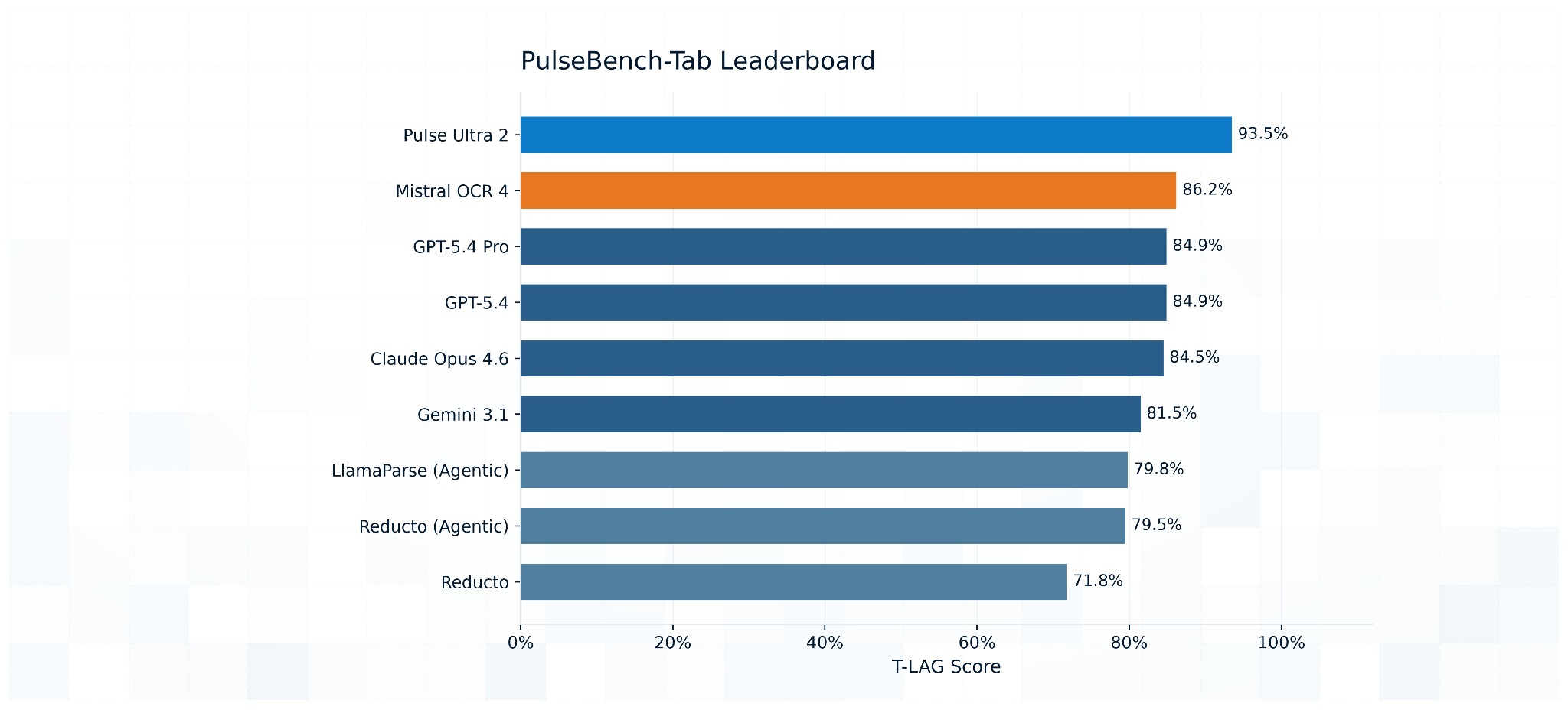
At 86.2 T-LAG it lands second on the board to Pulse Ultra 2 (state-of-the-art), ahead of the frontier general-purpose models including GPT-5.4 Pro and Claude Opus 4.6, as well as Gemini 3.1 and other agentic parsers.
The gap that remains is the one that matters for the documents our customers actually run, where Pulse Ultra 2 holds a roughly seven-point lead at 93.5 T-LAG. That margin comes from the cases PulseBench-Tab was built to stress, including merged cells, nested headers, footnoted figures, and tables that break across pages or languages. Those are exactly the structures where a few points of T-LAG translate into the difference between a clean extraction and one that needs a human to repair it, and they remain the frontier of the problem rather than a solved corner of it.
The broader takeaway is that table extraction is approaching higher and higher accuracy, which is great for clients and everyone building on document AI. It also confirms why we keep PulseBench-Tab public and keep running new models through it. The full benchmark, methodology, and document set are available for anyone who wants to reproduce these numbers or test against their own corpus.

