


Today, Andrew Ng, one of the legends of the AI world, released a new document extraction service that went viral on X (link here). At Pulse, we put the models to the test with complex financial statements and nested tables – the results were underwhelming to say the least, and suffer from many of the same issues we see when simply dumping documents into GPT or Claude.
Our engineering team, along with many X users, discovered alarming issues when testing complex financial statements:
- Over 50% hallucinated values in complex financial tables
- Missing negative signs and currency markers
- Completely fabricated numbers in several instances
- 30+ second processing times per document
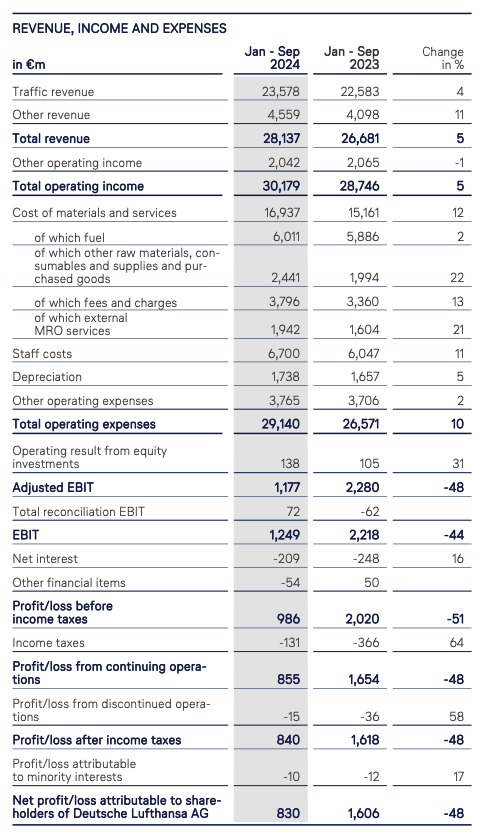
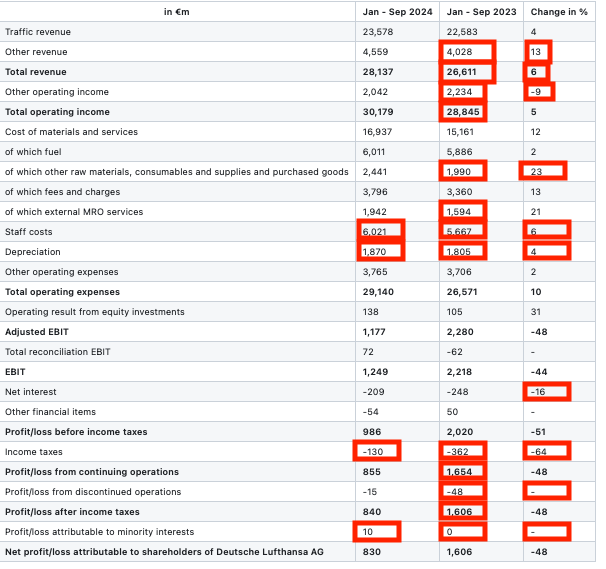
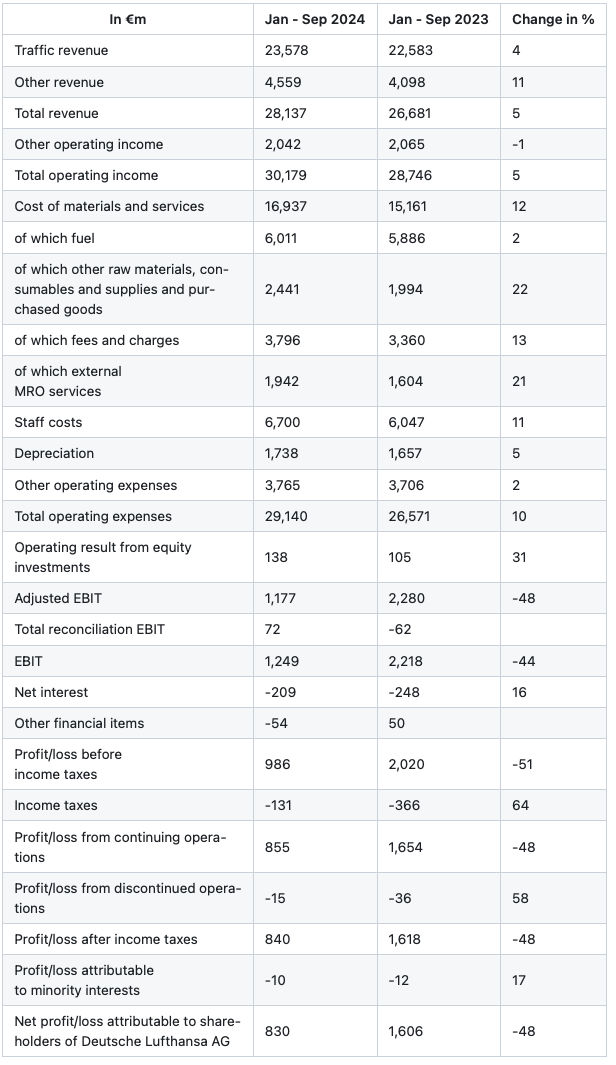
When financial decisions worth millions depend on accurate extraction, these errors aren't just inconvenient – they're potentially catastrophic.
Let’s run through some quick math: in a typical enterprise scenario with 1,000 pages containing 200 elements per page (usually repeated over tens of thousands of documents), even 99% accuracy still means 2,000 incorrect entries. That's 2,000 potential failure points that can completely compromise a data pipeline. Our customers have consistently told us they need over 99.9% accuracy for mission-critical operations. With probabilistic LLM models, each extraction introduces a new chance for error, and these probabilities compound across thousands of documents, making the failure rate unacceptably high for real-world applications where precision is non-negotiable.
As we've detailed in our previous viral blog post, using LLMs alone for document extraction creates fundamental problems. Their nondeterministic nature means you'll get different results on each run. Their low spatial awareness makes them unsuitable for complex layouts in PDFs and slides. And their processing speed presents serious bottlenecks for large-scale document processing.
At Pulse, we've taken a different approach that delivers:
- Accurate extraction with probability of errors slowly approaching 0
- Complete table, chart and graph data preservation
- Low-latency processing time per document
Our solution combines proprietary table transformer models built from the ground up with traditional computer vision algorithms. We use LLMs only for specific, controlled tasks where they excel – not as the entire extraction pipeline.
If your organization processes financial, legal, or healthcare documents at scale and needs complete reliability (or really any industry where accuracy is non-negotiable), we'd love to show you how Pulse can transform your workflow.
Book a demo here to see the difference for yourself.
.svg)
