


Table extraction is the hardest unsolved problem in enterprise document intelligence. A column swap, a missing header, or a misaligned merge does not just look wrong on a page. It corrupts the financial models, compliance workflows, and analytics pipelines built downstream. The cost of a silent table extraction error is categorically different from a text OCR mistake.
RD-TableBench, published by Reducto, is one of the benchmarks used in the space. The dataset, provider outputs, and scoring code are public. We ran Pulse Ultra 2 through RD-TableBench using Reducto's published ground truth and their published Needleman-Wunsch scoring methodology, with no modifications and no corrections, on the same evaluation pipeline Reducto uses to score its own systems.
The Results
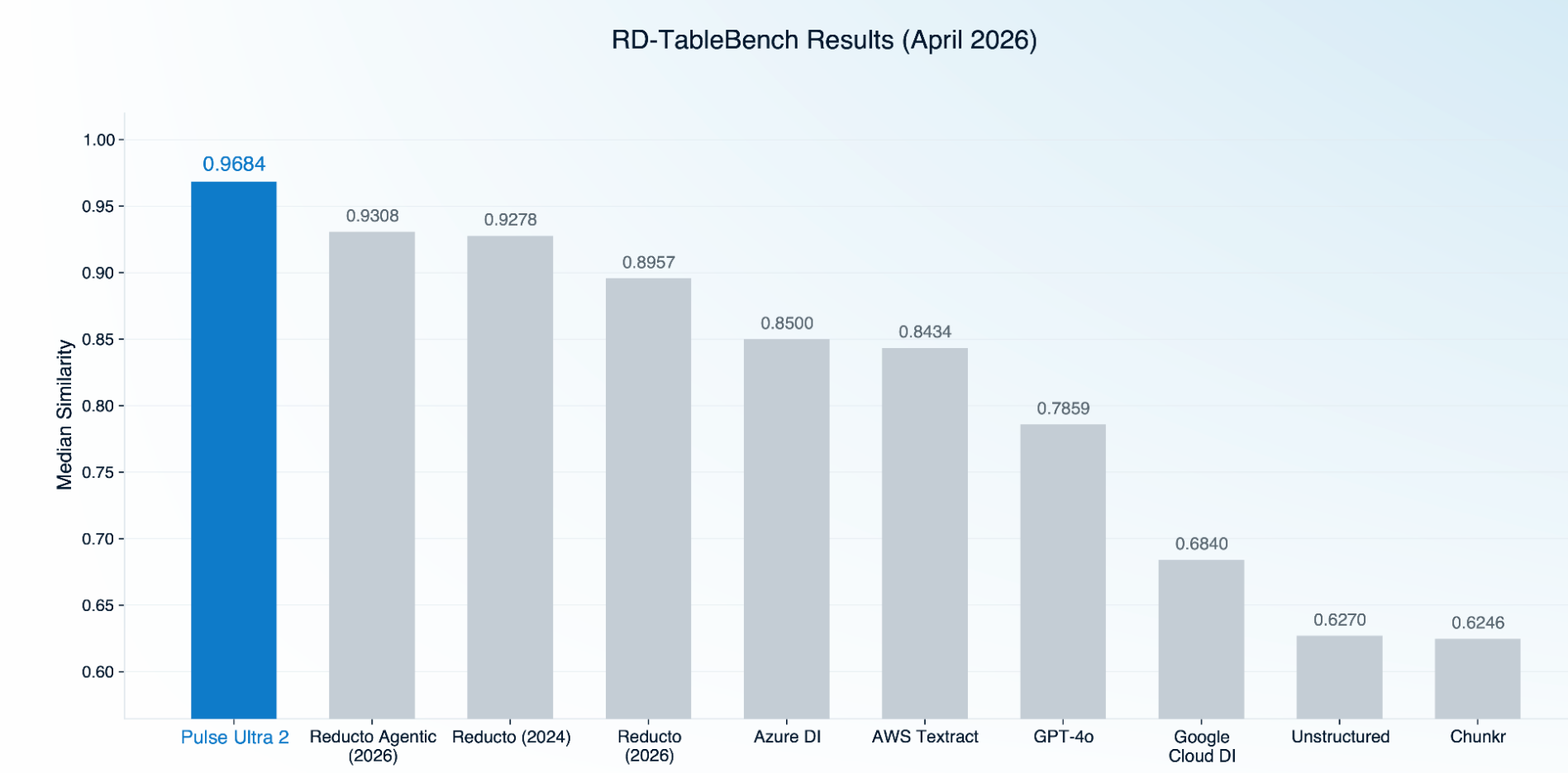
The gap between Pulse Ultra 2 and the next system is 3.76 points.
What This Means
Pulse Ultra 2 leads RD-TableBench despite being a single-pass model evaluated against systems that take multiple inference passes to produce their output. The result on Reducto 2024 versus Reducto 2026 is also worth noting, because the 2024 model scores higher than the 2026 non-agentic release on this benchmark, which suggests that gains on RD-TableBench from incremental changes inside any single provider are getting harder to come by. The frontier is moving, and the systems that are moving it are the ones investing in better training data and better vision language model architectures rather than incremental rule-based or layout-based improvements.
For enterprise teams evaluating table extraction providers, the practical takeaway is that the gap between the best and the rest on complex tables is now meaningful enough to show up in production. A 3 to 4 point median similarity difference compounds across millions of pages into thousands of corrected cells, and corrected cells translate into reduced reconciliation work, fewer downstream model errors, and fewer compliance escalations.
Ground Truth Quality
Earlier this week we published a longer piece on table extraction benchmarks broadly, which included an audit of RD-TableBench's ground truth. That audit identified 43 ground truth files (4.3% of the 1,000-sample dataset) with verifiable errors when compared against their source images, including scrambled column headers, garbled OCR transcriptions, and buffer artifacts attached to numeric values. We also found that 89 of the 1,000 ground truth files are byte-for-byte identical to Reducto's provider output, and that in 15 of the 43 verified errors, the ground truth and Reducto's output share the exact same specific error while independent providers do not.

The result above (0.9684 median similarity) was computed on the original, uncorrected ground truth. On a benchmark that includes ground truth with shared-error patterns favorable to Reducto's outputs, Pulse Ultra 2 still leads the field by a wide margin. When we re-scored with corrected ground truth on the affected samples, Pulse Ultra 2's lead expanded further, with the largest individual sample drops landing on Reducto's outputs (-14.0% on sample 28612, -12.5% on sample 29887, -6.6% on sample 594). Full audit methodology and per-sample results are in the longer benchmark post.
We are flagging this in the interest of community transparency, not as a competitive argument. Pulse Ultra 2 leads the benchmark on the original ground truth, and the audit findings are about benchmark integrity that apply to anyone using RD-TableBench to evaluate table extraction providers.
What's Next
We built PulseBench-Tab in part because we wanted a multilingual, 2D-aware, fully open benchmark that could complement RD-TableBench rather than replace it. PulseBench-Tab covers 1,820 tables across 9 languages, including RTL scripts and CJK, with diagnostic breakdowns by language, structural complexity, and merged cell presence. The dataset, the ground truth, the scoring code, and the per-sample results are all public.
Pulse Ultra 2 is available now through Pulse's standard API, VPC, and on-prem deployments. If you are evaluating table extraction at scale, we are happy to run your documents through it and share the per-sample output for your team to inspect.

