


After processing nearly 500 million pages of enterprise documents, we've discovered that the biggest challenge in document AI isn't character recognition or table extraction. It's something far more fundamental: understanding how information flows across page breaks, column boundaries, and interrupted sections.
Current AI models excel at processing individual pages in isolation. But real business documents don't respect page boundaries. Critical information spans pages, sentences break mid-thought across columns, and logical document sections get fragmented by layout constraints.
This isn't just a technical limitation - it's an architectural blind spot that makes enterprise document processing unreliable at scale. We discovered this was a fundamental issue after dealing with hundreds of various document layouts and types.
Here’s an example exemplifying what we already know: humans can easily parse through reading order for newspapers, understand context between multi-column financial statements, but VLMs break without special algorithms.

The Page Break Problem
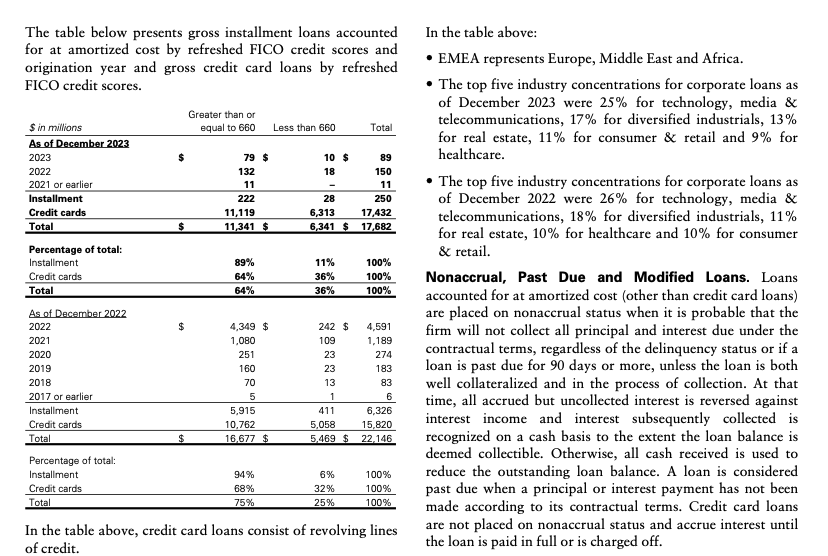
Business documents treat pages as physical constraints, not logical boundaries. A financial statement might have a table header on page 3 and corresponding data on pages 4-7. A legal contract's definition section on page 1 applies to clauses scattered throughout the remaining 50 pages.
Current document AI processes pages sequentially, losing these cross-page relationships. Financial reports suffer when multi-page tables have column headers that appear once but data that spans dozens of pages.
When processed page-by-page, rows become meaningless without their header context. Legal contracts break when cross-references like "as defined in Section 2.1(a)" become orphaned links between definitions and references on different pages. Technical specifications lose coherence when equipment manuals have diagrams on page 12 that explain procedures detailed on pages 15-18, and the semantic connection between visual and textual information disappears.
The Multi-Column Maze
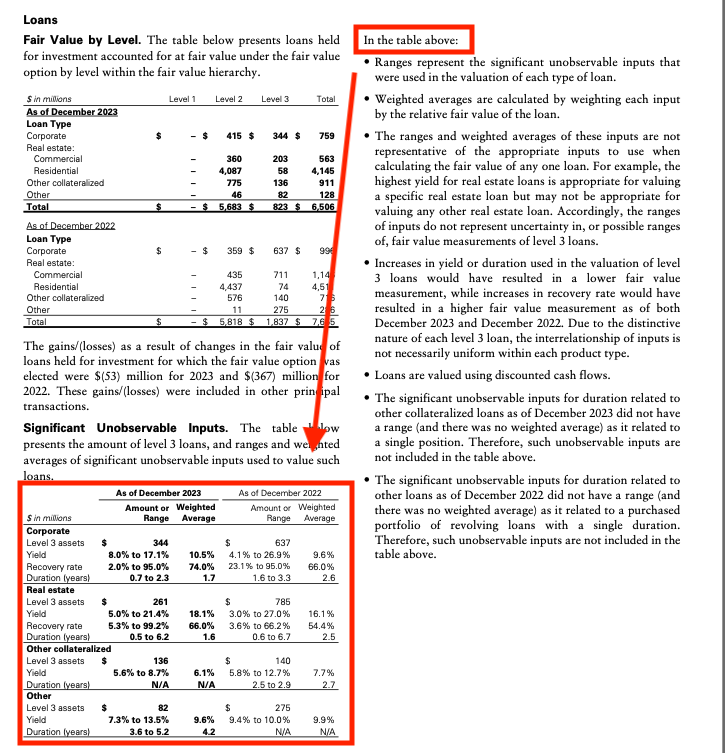
Academic papers, financial reports, and technical documents frequently use multi-column layouts that create reading order complexity invisible to standard processing pipelines.
Take this common layout in financial statements:
Left column: "Our quarterly revenue analysis shows significant growth in the technology sector. This trend continues into the next quarter where we expect..."
Right column: "...additional expansion in cloud services. Meanwhile, our healthcare division reported different results entirely..."
The sentence that starts in the left column doesn't finish until you jump to the right column. But then that same right column immediately shifts to talking about healthcare, a completely different topic.
AI models typically process content in raster order (left-to-right, top-to-bottom), fragmenting logical narrative flow and creating incomprehensible text sequences.

The Semantic Fragmentation Effect
We've observed systematic patterns in how semantic understanding breaks down across document boundaries.
Reference resolution failures plague enterprise documents when "See Appendix C" becomes meaningless because Appendix C is processed separately. As a result these footnotes lose connection to their referenced data, and legal subclauses become orphaned from their parent sections.
Context window limitations compound the problem as models process documents in chunks that don't align with logical sections, important context from page N-1 gets lost when processing page N, and cross-page calculations become impossible to verify.
Perhaps most critically, hierarchical structure collapse destroys document logic when outlines spanning multiple pages lose their nested relationships, table of contents references become unresolvable, and section numbering systems break when processed piecemeal.
What Actually Works
Effective document processing requires semantic-aware algorithms that understand document structure before extraction. This means document structure analysis through pre-processing that identifies logical document sections, reading order, and cross-page relationships.
Contextual memory in processing approaches maintains relevant context across page boundaries instead of treating each page as an independent unit.
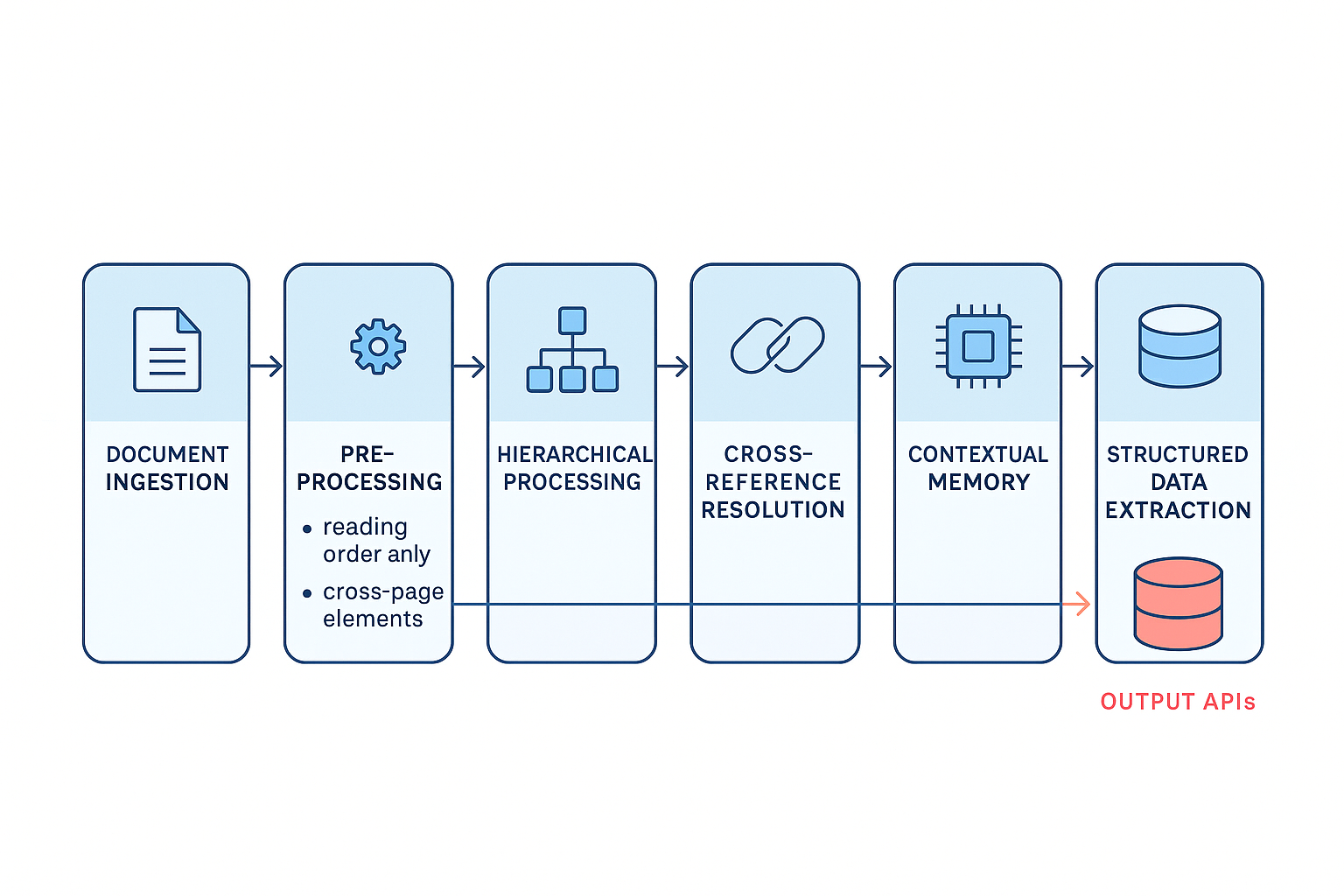
The future belongs to systems that can read documents the way humans do: understanding semantic flow, maintaining context across boundaries, and preserving logical relationships regardless of physical layout constraints.
Until we solve semantic continuity, document AI will remain a powerful tool for simple tasks but inadequate for the complex, multi-page, cross-referenced documents that drive enterprise operations.
The semantic understanding problem is the next frontier. The organizations that solve it will define the future of document intelligence.
—
At Pulse, we're working on document processing systems that maintain semantic understanding across page breaks, column boundaries, and complex layouts.

