


Most document extraction systems in production today treat the task as conditional sequence generation. A model ingests pixels or tokens, learns a distribution P(y | x) over output sequences given the document, and samples or beam-searches its way to something that looks like structured data. The training objective is cross-entropy against a flattened target, the inference procedure is autoregressive, and the output is whatever string the decoder happens to land on. This framing has carried the field a long way, and for casual use cases it works well enough. For regulated documents it is the wrong abstraction, and the consequences show up in exactly the places enterprises care about most, including audit defensibility, reconciliation overhead, and the quiet failures that only surface three quarters later.
Regulated documents are not arbitrary strings, they are structured artifacts governed by domain rules that have held for decades and are often codified in law or accounting standards. A balance sheet that does not balance is not a balance sheet, a loss triangle with development factors that drift in the wrong direction is not a loss triangle, and a healthcare claim with mutually exclusive procedure codes is not a valid claim, it is a rejection waiting to happen. When extraction systems ignore these rules during decoding they produce output that is syntactically plausible and semantically impossible, which means a downstream reviewer has to catch it.
The better framing is an old one from classical AI, namely constraint satisfaction. Formally, extraction becomes the problem of finding an assignment A over schema variables V that maximizes P(A | document) subject to a constraint set C, where each constraint c ∈ C encodes a domain rule that any valid document must satisfy. The model still does the heavy lifting of perception, but decoding is no longer a free-running autoregressive walk over a token vocabulary. It becomes a search over the feasible region of a typed output space, with infeasible assignments pruned before they are ever scored.
What the constraints actually look like
The constraints are not exotic, they are the basic grammar of the domains themselves, and most of them reduce to linear equalities, inequalities, monotonicity conditions, or categorical exclusions.
In financial statements the accounting identity holds everywhere. Assets equal liabilities plus equity, the indirect cash flow statement reconciles to the period change in cash on the balance sheet, and net income flows from the income statement into retained earnings via the standard articulation. These are not soft preferences, they are definitional equalities, and they can be expressed as a small set of linear constraints over the extracted variables. An extraction system that returns a balance sheet off by a hundred million dollars because it misread a parenthesis as a minus sign has not made a small error, it has produced an assignment that violates A = L + E. A constraint-aware decoder rejects the assignment before it is emitted and reallocates probability mass to the feasible neighborhood.
Insurance actuarial triangles carry structure that is naturally expressed as constraints over a matrix. Cumulative paid and incurred losses must be monotonic across development periods, which is a pairwise inequality over cells in each row, and age-to-age development factors generally decay as claims mature, which is a weaker monotonicity condition over ratios. Individual diagonal entries must be consistent with the valuation date implied by the triangle header, which is an equality constraint that couples the schema to document-level metadata. An extraction system that silently produces a triangle violating row monotonicity has handed the actuary a puzzle she did not ask for, and one she cannot resolve without going back to the source.
Healthcare claims are governed by NCCI procedure-to-procedure edits and medically unlikely edits, which together define a combinatorial exclusion structure over CPT and HCPCS code pairs on a single claim. The rules are enumerable, public, and deterministic, which means they can be compiled into a constraint graph and checked during decoding rather than after submission. An extraction system that returns a claim with a bundled pair of codes has produced something that will be rejected on adjudication, and the extraction was effectively useless regardless of how confident the token-level model was.
Credit agreements carry one of the densest constraint structures in regulated finance. Defined terms in the Section 1 definitions govern the entire document, which is a referential integrity constraint structurally identical to scope resolution in a typed language, so that every subsequent use of Consolidated EBITDA or Permitted Indebtedness must resolve to the same definition across dozens of sections. Financial covenants impose joint constraints that tie the covenant level, the test period, and the calculation methodology together, so that an extracted leverage test of 4.5x is only meaningful if the trailing-twelve-month basis and the quarterly test frequency are extracted consistently with it. Negative covenant baskets and carveouts encode linear constraints with explicit cross-section dependencies, where utilization under one basket reduces availability under another, and the document is threaded with section cross-references that must resolve to existing sections under the conditional logic the agreement itself specifies. An extraction system that treats these as independent fields will produce a document where individual values look correct but the agreement as a whole is internally broken, which is exactly the failure mode covenant monitoring systems are supposed to prevent.
Why sequence models miss this
An autoregressive decoder factorizes P(y | x) as a product of conditional token probabilities and commits left to right, so it cannot enforce joint constraints over non-adjacent outputs or revise a number in light of what comes later. Cross-entropy rewards local plausibility and is blind to global consistency, so the property that a column sum equals the reported total never enters the gradient and the constraint stays invisible to the loss.
To see this clearly, take the simplest possible case, a document that is trivially easy to read. Schedule D Section 7.A of a Form ADV Part 1A filing is a clean government form, and any competent vision-language model will perceive its contents correctly on the first pass. Perception is not where the failure happens. What the page contains is three different constraint types layered on top of each other. Item 5 is a sixteen-way “check all that apply” list of affiliation types, and ticking 5(p), sponsor or general partner of pooled investment vehicles, creates a cross-schedule expectation that corresponding fund entries appear in Section 7.B.1. Items 6 and 7 encode a control relationship through a pair of yes/no questions whose joint answer must resolve to a coherent structure. Item 8 is a conditional cascade where 8(a) no should null out 8(b) and 8(c), so an extraction that returns 8(a) no while populating 8(c) with a custody address has produced an assignment that cannot be reconciled with the form’s own logic. A sequence model can read every field on this page correctly and still emit an invalid assignment, because the decoder has no representation of the constraints that tie the fields together. The failure is not perceptual, it is structural.

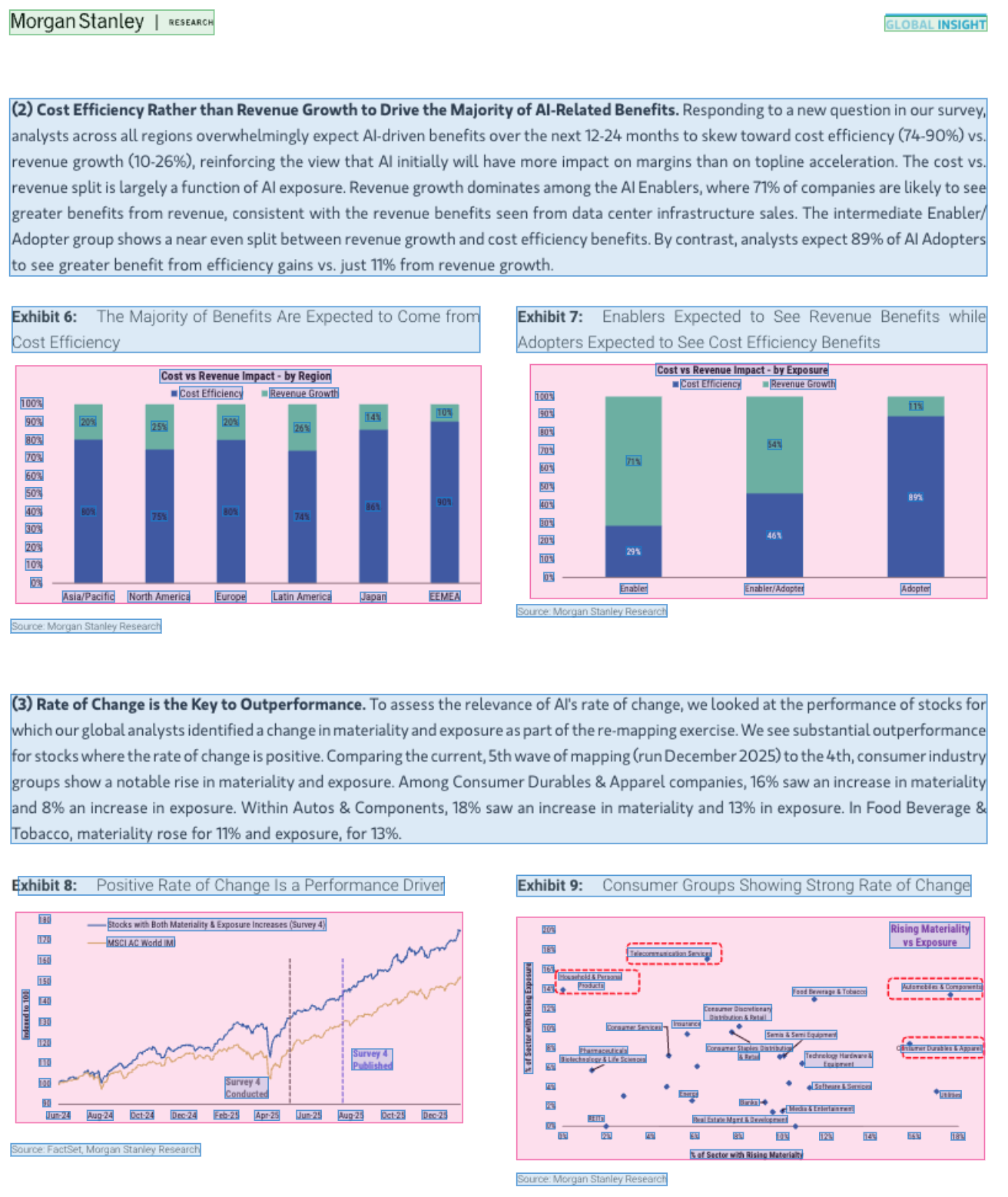
The same failure mode scales to documents where perception is harder and the constraints cross modalities. Take a page from a recent Morgan Stanley research note on AI adoption. The prose claims 89% of AI Adopters expect greater benefit from efficiency gains, and Exhibit 7 shows exactly that number on the Adopter bar. Each stacked bar in Exhibits 6 and 7 must sum to 100 percent, a linear equality over every column’s cost-efficiency and revenue-growth values. And the three sectors the prose calls out for rate-of-change analysis, Consumer Durables & Apparel, Autos & Components, and Food Beverage & Tobacco, must be the same three sectors highlighted in Exhibit 9, with matching materiality and exposure percentages. A sequence model can extract every number correctly and still produce a document where the prose statistics disagree with the exhibit values, the stacked bars fail to sum, or the sectors cited in the narrative do not match the ones annotated in the scatter plot. The constraints are cross-modal, the failure is still structural, and a constraint-aware decoder enforces consistency during inference rather than discovering the mismatches downstream.
Constraint propagation during decoding
The fix is to treat the schema and its rules as first-class inputs to the inference procedure. At each decoding step the set of feasible next tokens is intersected with the projection of C onto the partial assignment built so far. When the asset side of a balance sheet has been emitted, the liability and equity fields are no longer free variables, they are constrained by A = L + E and by the subtotal structure of their own hierarchies. Probability mass that would have been spent on infeasible completions is renormalized over the feasible set, which is both a correctness improvement and, in practice, an accuracy improvement on the feasible variables themselves, because the model is no longer competing against its own infeasible hypotheses.
Mechanically this looks like constrained beam search with a feasibility oracle, or like a decoder that emits into a typed structured output and invokes a propagator after each partial commit. SAT solvers, theorem provers, and type checkers have operated on this pattern for decades. What is new is composing it with vision-language models on regulated documents at enterprise scale, where the constraints are well-specified, the schemas are stable, and the cost of silent errors is high enough to justify the additional engineering in the decoder.
Why this matters for regulated industries
The case for constraint satisfaction is strongest exactly where the stakes are highest. A team extracting data from a pitch deck can tolerate an occasional off-by-one error because the downstream consequence is a revised slide, but a bank extracting call report schedules across millions of filings cannot, because the downstream consequence is a regulatory submission. Audit defensibility is not a feature that can be bolted on after extraction, it has to be structural, which means the extraction system itself has to refuse to produce infeasible output rather than relying on reviewers to catch it.
This also changes how accuracy should be measured. Field-level accuracy on independently scored cells tells you how often the model reads a number correctly, but it does not tell you how often the extracted document as a whole satisfies the constraints that define it, and for regulated workflows the second metric is the one that determines whether the extraction can be trusted without line-by-line human review.
Teams building extraction pipelines for regulated domains should stop thinking of the schema as a destination format and start thinking of it as a decoding constraint. The schema, the domain rules, and the cross-field relationships are not post-processing concerns, they are part of the inference problem, and the errors that remain after they are treated that way are the errors worth a human's time.

