


The Difference Between Reading and Ingestion
LLMs have made document AI feel deceptively simple. Upload a PDF, ask for Markdown or JSON, and the model will usually return something that looks clean. The hard part is not getting a model to read one document once. The hard part is turning millions of documents into secure, deterministic, auditable data that downstream systems can trust.
This is the difference between reading a document and ingesting one. Reading means understanding the general content. Ingestion means preserving exact text, numbers, tables, layout, hierarchy, citations, and source evidence. A chatbot can summarize a filing even if it misses a footnote. On the other hand, a production ingestion system cannot move a decimal point, drop a table row, attach a value to the wrong header, or invent a field that was never in the source.
Silent Failures and Hallucinations
The biggest risk with LLM-based parsing is not obvious, it is silent failure. The output often looks polished where the markdown is readable, even the JSON validates properly, and table structures appear coherent. But underneath, rows may be missing, columns may shift, headers may collapse, and values may be normalized incorrectly.
This is especially dangerous for any regulated industry - in finance, insurance, legal, healthcare, procurement, and compliance workflows, where one incorrect field can corrupt a model, claim, contract review, or downstream system. A model hallucinating in an ingestion pipeline can poison a database.
Why Tables Break LLM-Only Parsing
Tables are the clearest example of why document parsing cannot be reduced to one model call. A table is not simply text arranged on a page. It is a two-dimensional structure where each value depends on the row label, column label, section header, unit, and footnote around it.
If a parser extracts the right number but places it under the wrong header, the data is still wrong. If it collapses a spanning header, drops an empty cell, duplicates a merged cell, or loses a table continuation across pages, the output may still look clean while the underlying data is corrupted.
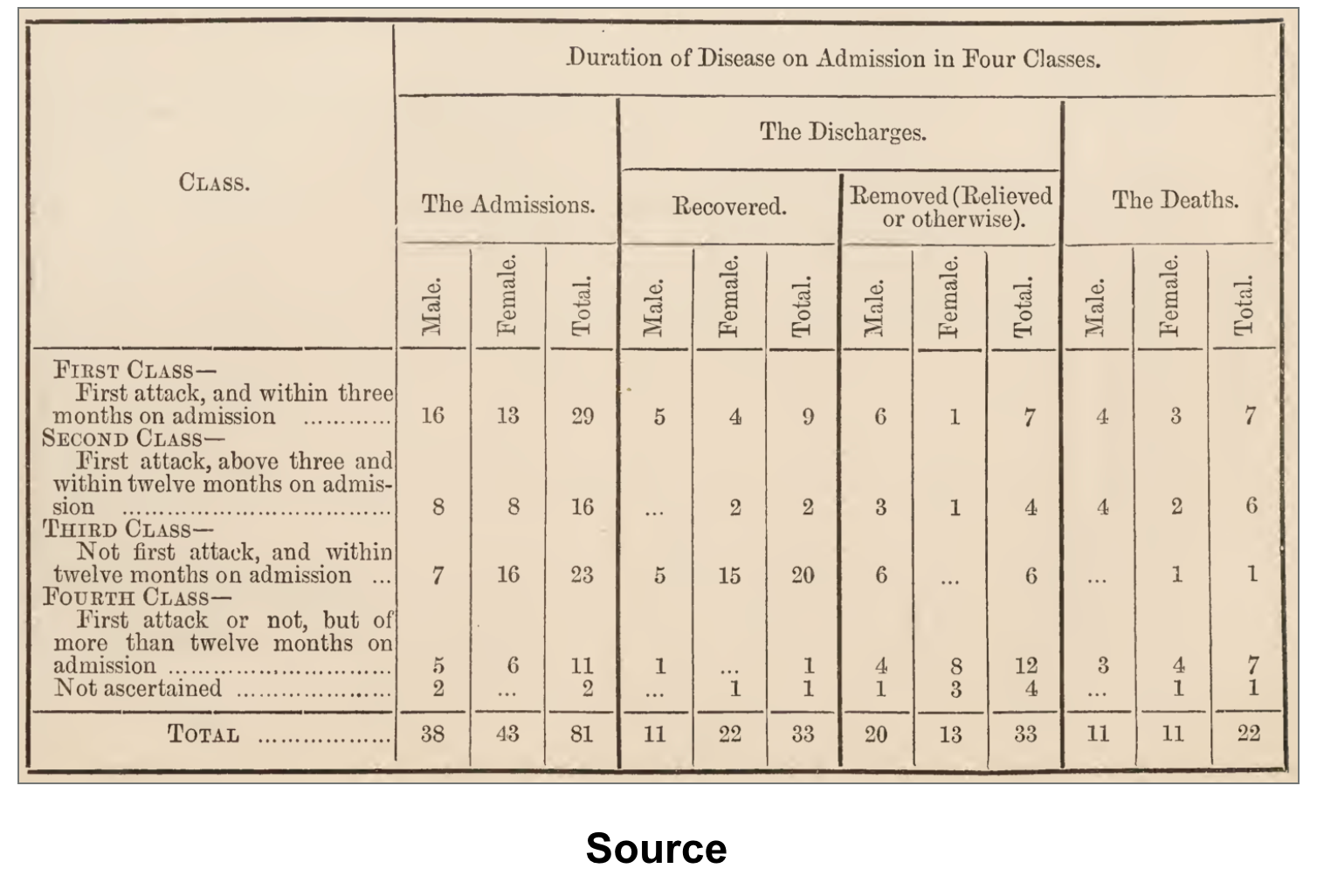
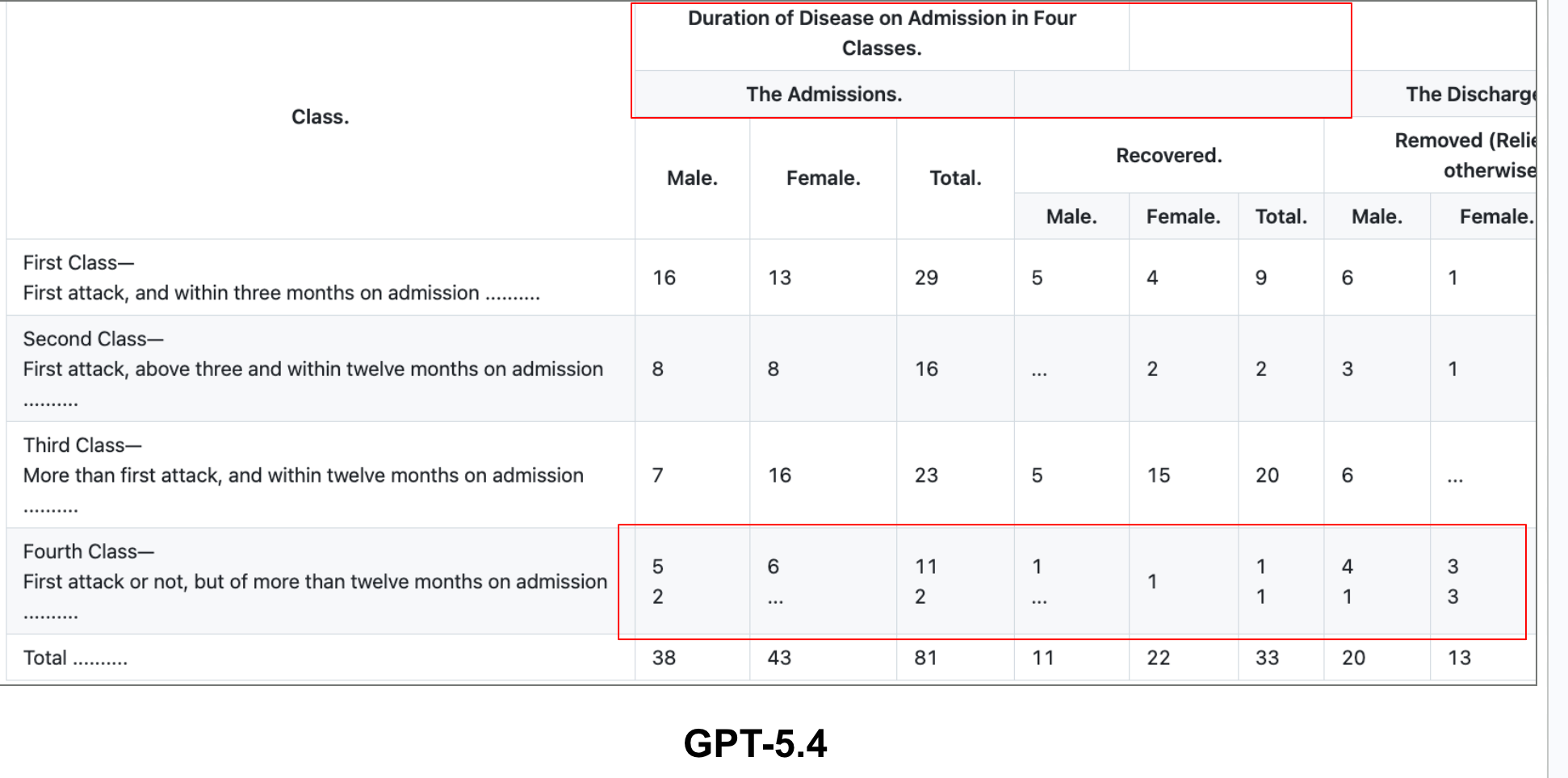
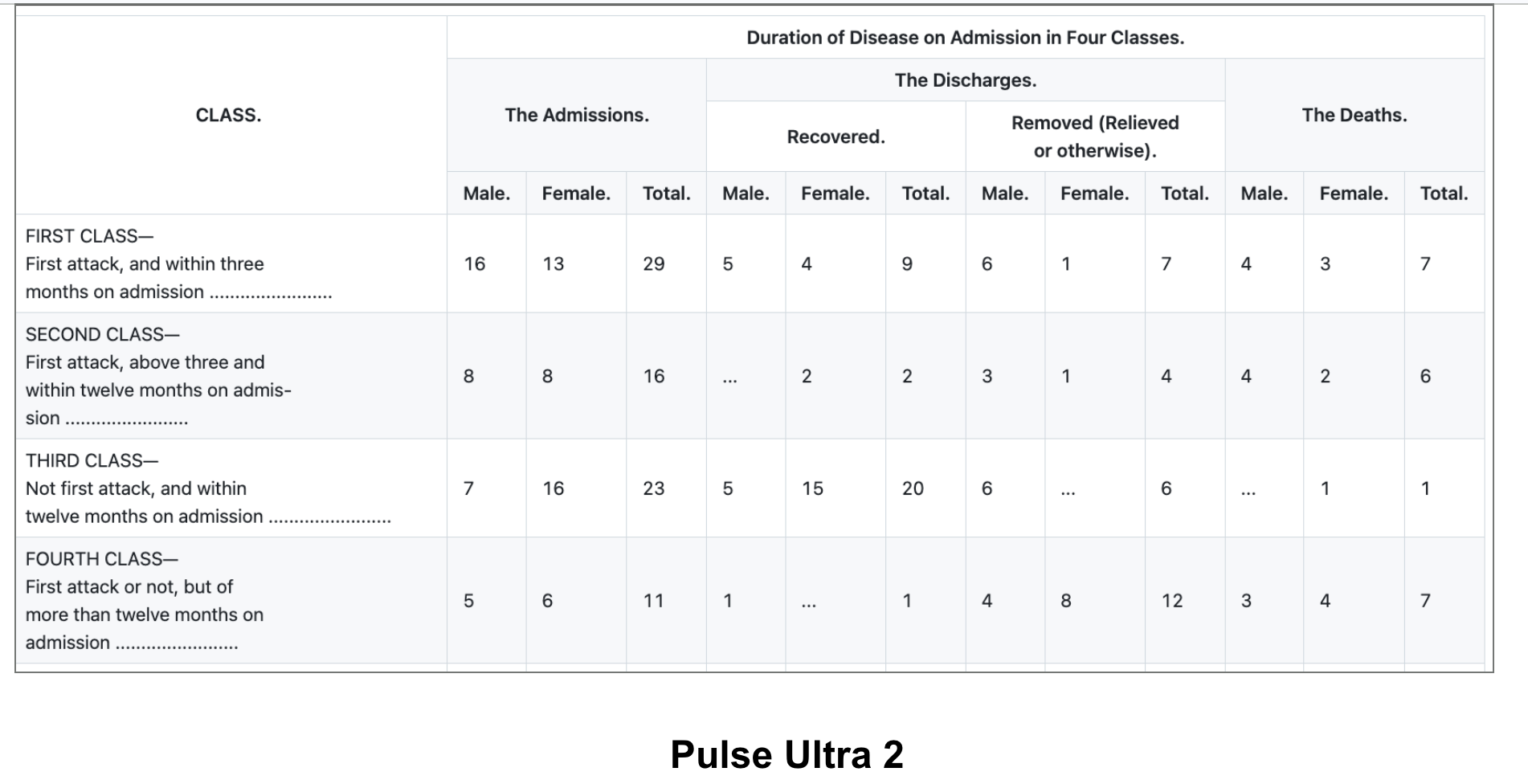
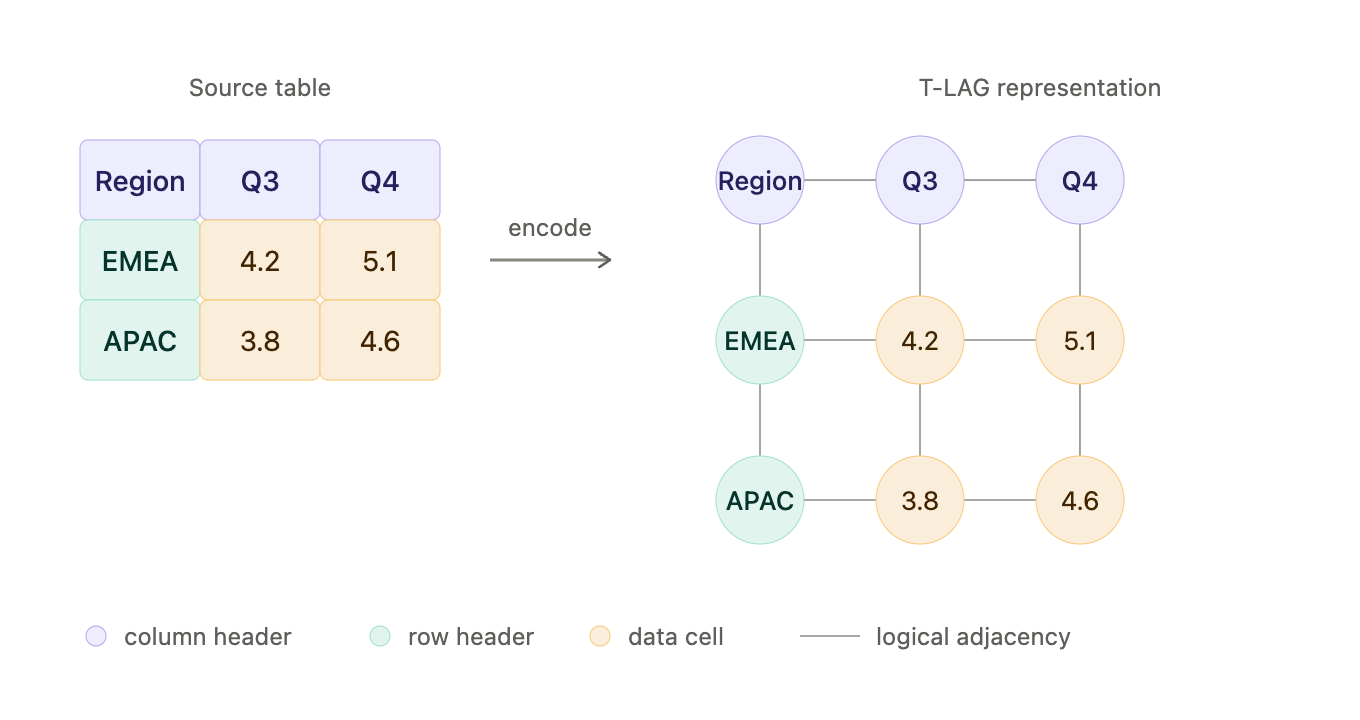
What PulseBench-Tab Shows
This is why we released PulseBench-Tab, an open multilingual benchmark for table extraction from document images. PulseBench-Tab contains 1,820 real-world tables across 9 languages, drawn from 380 source documents, with 48% of samples containing spanning cells. It evaluates providers using T-LAG, which encodes each table as a labeled adjacency graph where cells are typed by role and edges capture logical structure, scoring extraction by how closely the predicted graph matches ground truth.
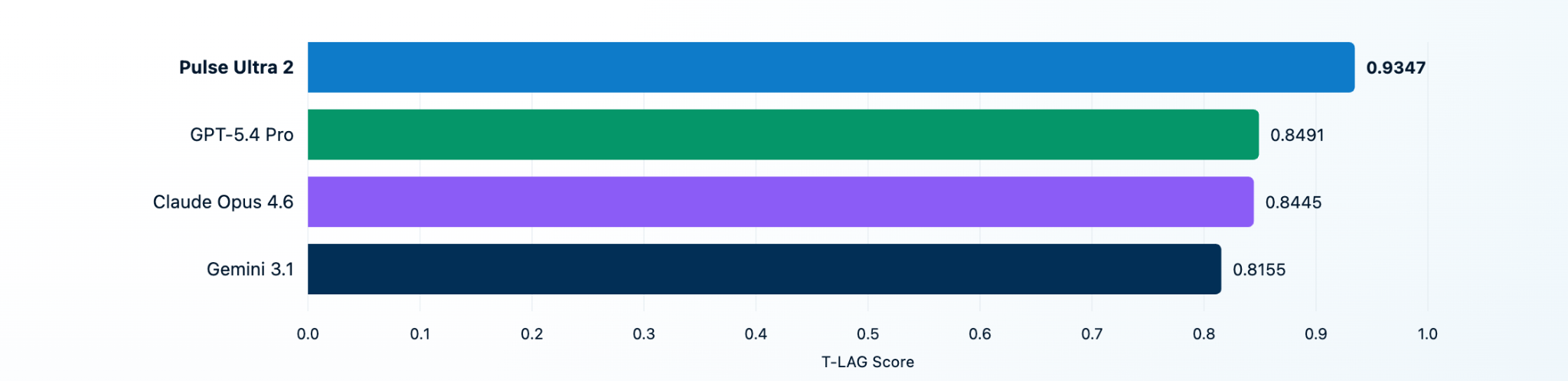
The results show that document extraction is still far from solved. Pulse Ultra 2 scored 93.5%. The next highest listed system, GPT-5.4 Pro, scored 84.9%, Opus 4.6 at 84.5%, and Gemini 3.1 at 81.5%,
Determinism, Auditability, and Security
Enterprise parsing also requires repeatability. If the same document is processed twice with the same settings, the output should not change. If a field changes, the system should know why. Generic LLM workflows make this difficult because outputs can vary across runs, prompts can drift across long documents, and hosted models can change behavior over time. For enterprise ingestion, determinism is not a technical preference. It is the foundation for auditability.
Auditability means every extracted field should point back to the original page, source text, and ideally a bounding box. A revenue number, medical dosage, policy deductible, or contractual clause is only useful if a reviewer can verify where it came from. Without field-level provenance, document extraction becomes another black box.
Security changes the architecture entirely. The most valuable documents are often the most sensitive: financial statements, insurance claims, medical records, contracts, diligence materials, tax documents, and customer data. Many enterprises cannot send these documents to a third-party hosted model API. They need private deployment, VPC or on-prem support, zero data retention, customer-controlled keys, and the option to run models without external dependencies.


The Right Architecture for Enterprise Parsing
The future of document parsing is hybrid. You need computer vision for layout, OCR models for text, table-specific extraction for structure, language models for schema mapping, deterministic validation for business rules, and evidence tracking for auditability. Each component should do what it is best at.
LLMs are powerful, and they will be part of the stack. But enterprises do not need a model that can simply read a PDF. They need systems that can ingest documents, verify outputs, preserve provenance, and safely turn unstructured files into trusted data.

