


Energy is a sector that runs on documents at every layer of its operations, and the decisions that move it, from the allocation of capital at an integrated operator down to the daily accounting of work performed across power, utilities, and the oilfield, are made on the basis of a document stack that accumulates across decades and across every counterparty the business touches. Within that stack, the subset that presents the highest barrier to automation is not only the visually complex one, but just as often the transactional layer, the field tickets, service records, and hauling logs generated by a long tail of vendors in formats that almost never conform to the clean, consistent structure that general-purpose extraction systems are built to expect.
A single producing asset can generate thousands of field tickets in a month. Every load of produced water hauled off location, every hour a hot oil truck runs, every winch tractor and transport rig that moves equipment to a wellsite produces a ticket, and each of those tickets is the source record for what was done in the field and what it is going to cost. Long before any of that work shows up on a financial statement, it exists as a piece of paper or a scanned PDF handed off by a service vendor, and the entire job of cost control is to turn that pile of tickets into numbers the business can trust.
Field tickets come off the same operations that produce every other field record, written by hand in the cab of a truck or out on a wellsite, under the same conditions that produce hand-filled well reports, daily logs, and gauge sheets. They share that origin, and with it the same extraction challenge of handwriting, inconsistent structure, and degraded scans. What sets them apart is not how they are recorded but what they feed. A well report informs the reservoir model, while a field ticket sits squarely between the field and the ledger, carrying financial rather than geological meaning, which is exactly what makes getting it right at scale so consequential.
A Field Ticket Is a Financial Primitive
It helps to be precise about what a field ticket actually does downstream. Each ticket is the first link in a chain that runs through cost coding, accrual, invoice matching, and partner billing. The hours and rates on a ticket get coded against an authorization for expenditure so that spend can be tracked against budget. They get accrued at period close so the financials reflect work performed but not yet invoiced. When the vendor's invoice eventually arrives, the ticket is what the invoice gets matched against, the operational proof that the billed work really happened at the billed rate. And on jointly owned properties, those same ticket-level costs get allocated across working-interest partners through joint interest billing, where an error does not stay internal but propagates out to the people the operator bills.
In other words, every field ticket carries financial, contractual, and audit meaning. A misread rate or a dropped line item does not produce an obvious failure. It produces a number that is quietly wrong, and that wrong number flows into accruals, into invoice disputes, and into partner statements before anyone notices.
The Format Problem Nobody Designed
The reason field tickets resist automation has very little to do with the difficulty of reading text and almost everything to do with the fact that no two vendors produce the same ticket. An operator works with a long tail of service companies, and each one brings its own template, its own field names, and its own conventions, often filled out by hand in the cab of a truck.
The variation is relentless once the volume is high enough. One vendor's ticket carries a trucking company field that no other ticket has, while another drops the company name entirely and leads with a work ticket number. Dates appear as 3/25/26 on one ticket, as 4-29-26 on the next, and as a fully written 5/10/2024 on a third, with no guarantee that any of them used the format the system expects. Totals are even worse, showing up as a bare 480 here, a dollar-formatted 1,085 there, and a 6700 with no separators somewhere else, so that the same field is sometimes a clean number and sometimes a string that has to be parsed before it can be summed. Hours might read as a simple 5 on one ticket and as 20 for a transport truck plus 4 for a winch tractor on another, two numbers crammed into a single field with the equipment type interleaved. Load descriptions, operator names, start and end times, purchase order numbers: each appears on some tickets, is absent from others, and is positioned differently wherever it does appear.
On top of all that sits the handwriting. Scanned and photographed tickets degrade in predictable ways, and a vendor name or equipment type that a human reads instantly becomes something else entirely once it passes through conventional optical character recognition. A customer name gets transcribed three different ways across three tickets. An equipment line that should read winch tractor comes back as winch calor. None of these are catastrophic on their own, but a vendor name that does not match across tickets quietly breaks the very thing reconciliation depends on, which is the ability to group and match records that belong together.
Where the Money Leaks
When the only way to turn these tickets into structured data is manual entry, the costs accumulate in places that are easy to overlook. Coding teams and accounts payable clerks spend their time keying values off PDFs, which is slow, expensive, and itself a source of error. Tickets that arrive late or get entered inconsistently lead to missed accruals, so period close understates real spend. Invoices that cannot be cleanly matched to tickets either get paid without proper verification or get held up in dispute, and both outcomes are costly. On jointly owned assets, allocation errors turn into billing disputes with partners, which consume time and erode trust. And underneath all of it runs a steady stream of revenue and cost leakage, the unbilled work and the misbilled rates that never get caught because no one can reconcile thousands of inconsistent tickets by hand.
The deeper issue is that the field ticket layer is the foundation the rest of the cost stack is built on. Every system above it, the accrual process, the three-way match, the joint interest billing run, inherits whatever errors were baked in at the moment a ticket became a row in a database.
Why Conventional Tools Fall Short
Template-based extraction is the traditional answer, and it fails the moment a vendor changes a form or a new service company joins the roster. Maintaining a template per vendor across a long tail of suppliers is not a strategy, it is a treadmill. Rules-based parsing runs into the same wall, because the rules that handle one date format or one way of expressing hours break on the next ticket that does it differently. General-purpose language models can read a ticket, but they introduce their own problem, since they will confidently produce a value with no way to show where on the page it came from, and in a process where every number may have to survive an audit or a partner dispute, an answer that cannot be traced back to the source is not usable.
What Reconciliation-Grade Extraction Requires
Getting this right means treating field tickets as the financial records they are rather than as generic images to be transcribed. Pulse approaches the problem with vision-language models that read the layout of each ticket directly, which is what allows extraction to hold up across a constantly shifting set of vendor formats without a template for each one. The output is normalized to a single target schema, so a date written four different ways resolves to one consistent format, a total expressed as a string or a raw number resolves to a typed value that can actually be summed, and a field that one vendor includes and another omits is handled cleanly rather than silently dropped.
Just as important, every extracted value is grounded back to its exact coordinates on the source ticket. That source-level provenance is what makes verification fast during a three-way match and what gives an auditor or a partner a way to confirm a figure without digging through a stack of PDFs. Confidence scoring then does the triage, routing the handful of genuinely ambiguous fields to a human reviewer while letting the clean majority flow straight through, so the manual effort lands only where it is actually needed. And because the models are built for degraded and handwritten source material, the faded, skewed, and hand-filled tickets that defeat conventional tools stay readable. The same approach holds on hand-filled field documents of every vintage, including ones far rougher than any modern service ticket.
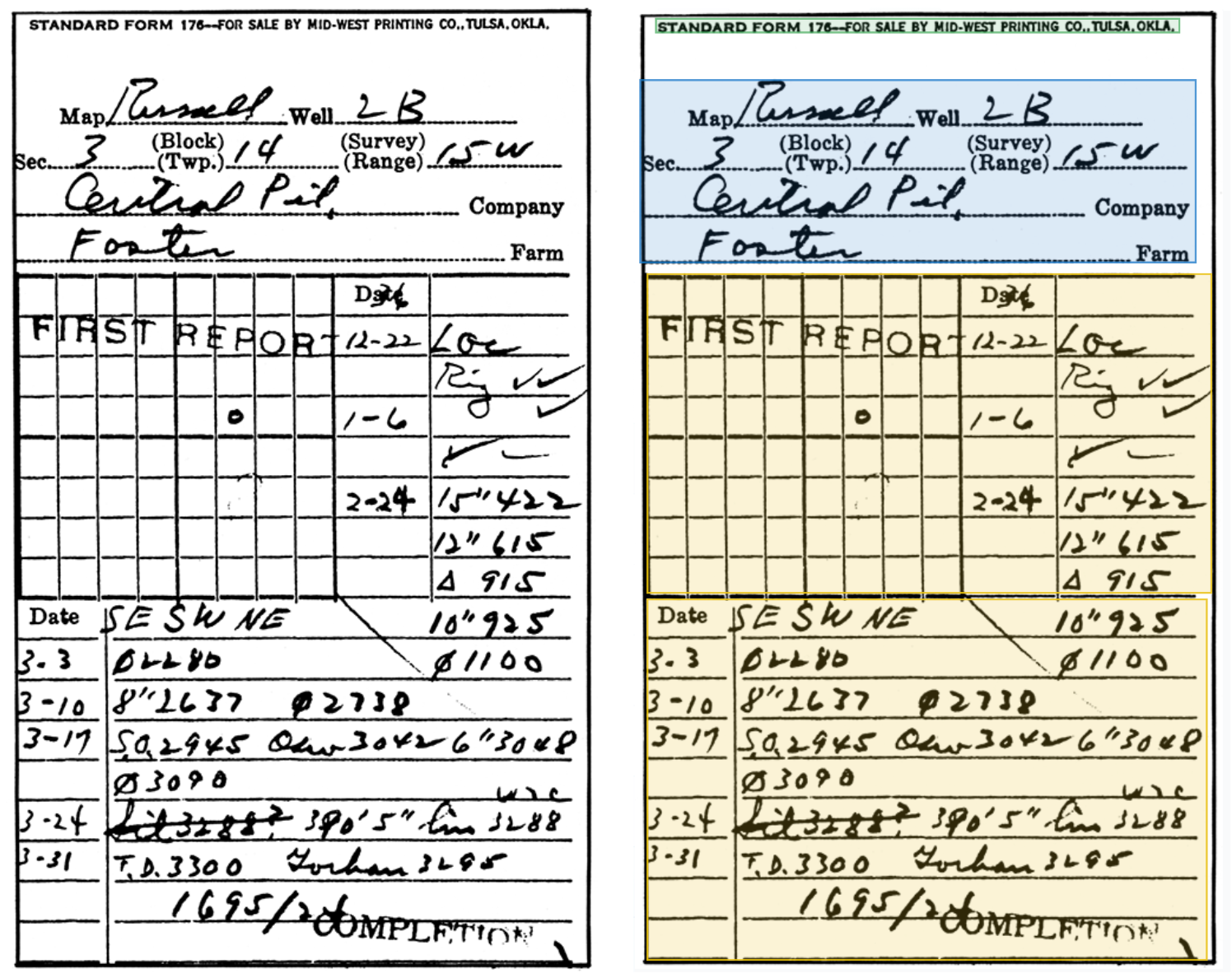
The result is a field-to-financials pipeline that produces structured, verifiable data fast enough to keep up with the volume the field actually generates, which is the difference between reconciliation that happens after the fact and reconciliation that keeps pace with operations.
The Quiet Foundation of Oilfield Cost Control
Subsurface documents get the attention because they drive the headline capital decisions, but the operational and financial integrity of an asset rests on a far less glamorous document type. Field tickets are the connective tissue between work performed and dollars accounted for, and an operator that can turn them into clean, traceable, structured data closes the gap between the field and the ledger. Pulse exists to close exactly that kind of gap, on exactly these kinds of documents.

