


DeepSeek AI just released DeepSeek-OCR, a new open-source model that aims to rethink text extraction through what it calls Context Optical Compression. The launch quickly caught attention on X and GitHub, with many celebrating another big step in open document AI.
At Pulse, we were curious how it performs on the kinds of messy, high-density documents that power real business workflows. So we ran DeepSeek-OCR through our standard evaluation suite: multi-page PDFs, handwritten forms, nested tables, and scanned statements. The results were promising in theory but inconsistent in practice.
Our Findings
- Bounding boxes were often misaligned or shifted slightly between runs, which makes it hard to use for precise coordinate-based extraction or audit trails.

- Outputs changed between runs, showing that the model is not deterministic. In regulated environments where repeatability is required, this makes validation difficult.

- Handwriting accuracy lagged behind classical pipelines. The model frequently hallucinated or skipped overlapping text, especially in scanned forms.
- Tables and reading order were the biggest challenge. We found multiple cases where cell structure broke down or column spans were misread, forcing manual checks. Our suspicion is that the Deepseek team did not have enough high quality training data on this task. Requires very thorough curation, which we know first hand!


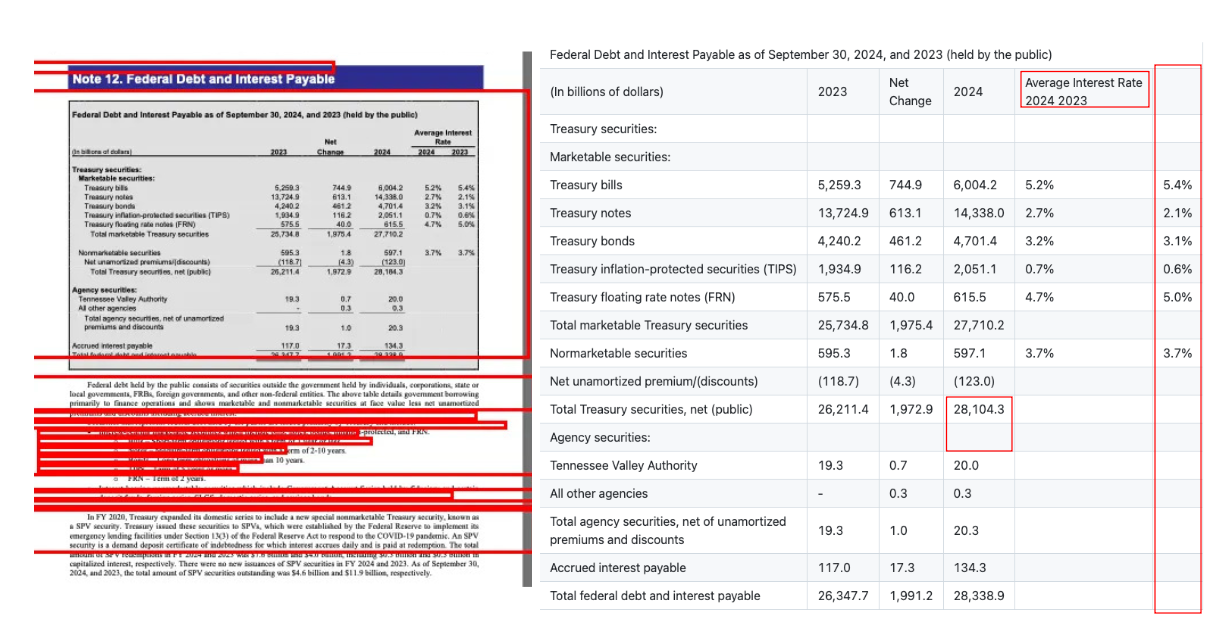
Despite these issues, it’s an impressive research release. The open nature and the idea of blending OCR with LLM grounding are exciting directions for the field.
Why This Matters
Document AI is at an inflection point. Models like DeepSeek-OCR show what’s possible when vision and language systems converge, but they also highlight why accuracy, determinism, and auditability still matter. In real production environments, even small deviations can ripple across entire data pipelines.
At Pulse, we’ve taken a different approach: purpose-built, deterministic models for layout detection, OCR, and table understanding, all working together in a controlled pipeline. It’s not as flashy as an end-to-end prompt, but it delivers the reliability enterprises need when precision is non-negotiable.
Takeaway
DeepSeek-OCR is an exciting milestone for open research and a clear signal that document AI is evolving fast. For experimentation and rapid prototyping, it’s a great step forward. For production-grade systems that demand guaranteed accuracy, there’s still work to be done.
We’re glad to see more innovation in this space and look forward to collaborating, benchmarking, and continuing to push the boundaries of reliable document intelligence.

