


Insurance, energy, and financial services are three of the most document-intensive and heavily regulated industries in the world, which means the documents they produce and consume are not just operational artifacts but legal records, compliance obligations, and audit trails that must be accurate, traceable, and readily accessible. And yet, across all three sectors, the same fundamental problem persists: critical business data remains trapped inside complex, unstructured documents that resist extraction by conventional tools, forcing skilled professionals to spend disproportionate amounts of time on manual data preparation rather than the analytical and decision-making work they were hired to do. This is not a new observation, but what has changed is that the technology to solve it has finally caught up with the complexity of the documents themselves.
The Shared Challenge
The surface-level details differ from one industry to the next, but the underlying pattern is remarkably consistent. In energy, a daily drilling report packs well identification metadata, time-stamped operations summaries, casing specifications, and mud properties into a single page of nested tables and free-text fields. In insurance, a commercial property submission might combine a broker's cover letter with an Acord application, a statement of values spreadsheet, loss runs from multiple carriers, and supplemental engineering reports, each in a different format. In financial services, a single investment due diligence package could include audited financial statements, partnership agreements, capital call notices, and portfolio company reports, often spanning hundreds of pages across PDFs, scanned images, and spreadsheets.
In each case, the documents are dense, structurally complex, and contain information that is only meaningful when the relationships between data points are preserved. A depth reading in a drilling report matters because of its association with a specific time entry and operation code. A coverage limit in an insurance submission matters because of its relationship to the underlying property schedule and loss history. A revenue figure in a financial statement matters because of the footnotes, adjustments, and accounting policies that qualify it. Flatten any of these documents into raw text and you lose the connective tissue that makes the data actionable.
Why Standard Extraction Tools Fall Short
General-purpose OCR and document processing platforms have improved significantly in recent years, but they were built for a different class of document: they excel at invoices, receipts, and simple forms where text is cleanly typeset, layout is predictable, and the mapping between visual position and semantic meaning is straightforward, while the documents that drive regulated industries are fundamentally harder.
Consider the daily drilling report from an energy company. A conventional extraction tool might successfully capture individual text strings from the page, but it will struggle to preserve the structure of the operations summary table, where time intervals, measured depths, activity codes, and narrative descriptions must all remain linked to be useful. It will likely misparse the casing and tubular information section, where column headers shift relative to the tables above and below. And it will almost certainly fail to connect the well metadata in the header block with the operational data in the body, which is the relationship that makes the report meaningful in the first place.
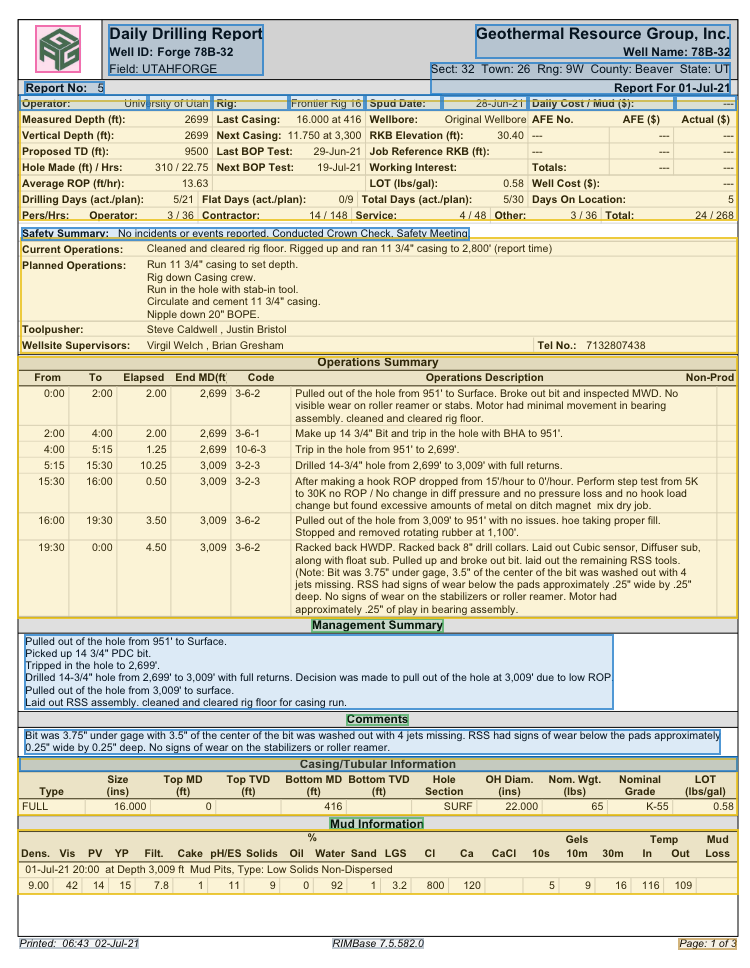
The same class of problem appears in insurance. A statement of values might arrive as a multi-tab spreadsheet embedded in a PDF, with merged cells, inconsistent column headers across tabs, and footnotes that qualify specific line items. An Acord form might be a fillable PDF that was printed, annotated by hand, scanned, and re-submitted as a flat image, while loss runs from different carriers follow different layouts entirely, which means that a tool incapable of reasoning about document structure, one that treats each page as an independent collection of characters, will produce output that requires as much manual cleanup as starting from scratch.
In financial services, the challenge is compounded by volume and time pressure, as a private equity fund evaluating a potential acquisition might receive a data room with thousands of pages of financial records, legal agreements, and operational reports, and its analysts need to extract specific data points, compare them across documents, and synthesize findings under tight deal timelines. When the source material includes scanned financial statements with complex table structures, multi-column partnership agreements, and capital account summaries with nested subtotals, the extraction problem becomes a genuine bottleneck on deal velocity.
The Shift to Structural Understanding
A new generation of document intelligence platforms, built on vision-language models rather than traditional OCR pipelines, is changing the calculus for regulated industries. These models are trained to understand documents the way a human analyst does: by jointly processing the visual layout, the textual content, and the structural relationships between them. Rather than treating a page as a grid of pixels to be converted into characters, a vision-language model interprets the document holistically, recognizing how tables, headers, narratives, and annotations relate to one another.
This structural awareness is what distinguishes modern document intelligence from legacy extraction. A few capabilities matter most across regulated industries:
Table extraction with relational context. Complex documents routinely contain tables where columns span multiple sections, units or categories shift mid-table, and footnotes qualify specific values. A daily drilling report might include an operations summary, a casing information table, and a mud properties table on the same page, each with a different column structure. An insurance submission might embed a statement of values with merged cells and conditional formatting. A financial statement might present a balance sheet with nested line items and cross-references to notes. Vision-language models can preserve these relationships in the extracted output, producing structured data that reflects how the document was actually organized.
Resilience to degraded and heterogeneous source material. Regulated industries accumulate documents over decades, and the source material reflects that history. Well files from the 1980s that have been photocopied and microfiched, insurance policies that were scanned from carbon copies, financial records that were faxed between counterparties: all of these degrade in ways that defeat conventional OCR. Models trained on diverse visual inputs can maintain extraction accuracy even when documents are faded, skewed, or partially obscured.
Unified processing across document types. A well file, an insurance submission package, and a financial due diligence data room all share a common characteristic: they are not single documents but collections of different document types that must be processed together. Rather than routing each type through a separate extraction pipeline, a unified platform can process the entire package and produce coherent, cross-referenced output.
Source-level provenance for every extracted value. In regulated industries, traceability is not optional, and every extracted data point should be linked to its exact location in the original document so that auditors, regulators, or internal quality teams can verify it without searching through hundreds of pages, a requirement that coordinate-level provenance makes fast and reliable.
Where This Matters Most
The impact of more accurate, scalable document extraction shows up wherever regulated industries face a mismatch between the volume of documents they need to process and the manual effort currently required to do so.
Subsurface analysis and drilling performance in energy. Evaluating play fairways across a basin requires synthesizing well data from dozens or hundreds of offset wells, many of which exist only as scanned records in geological survey archives. Daily drilling reports contain a granular, time-stamped record of every operation performed on a well, and when that data can be extracted at scale across hundreds of wells, it enables cross-well benchmarking and operational analysis that would be impractical to assemble by hand. Clean, structured output that flows directly into interpretation software like PETRA, Techlog, or Kingdom lets geoscientists spend their time on analysis rather than data wrangling.
Submission intake and underwriting in insurance. Commercial underwriting teams receive submissions that arrive as loosely organized bundles of PDFs, spreadsheets, and scanned forms, each in a different format depending on the broker and the line of business. Extracting the key data points needed for quoting and risk assessment (property values, coverage limits, loss history, building characteristics) typically requires an analyst to manually open, read, and re-key information from multiple documents, so automating this extraction compresses intake timelines and lets underwriters focus on risk judgment rather than data entry.
Due diligence and portfolio monitoring in financial services. U.S. upstream energy M&A alone reached $65 billion in 2025, and deal activity heading into 2026 is expected to remain robust across mid-cap transactions and bolt-on acquisitions. But the document processing bottleneck in due diligence extends well beyond energy. Any acquisition, whether of an E&P company, an insurance book of business, or a portfolio of financial assets, generates a data room full of documents that must be rapidly evaluated. When diligence timelines are measured in weeks, the ability to automatically extract and structure data from thousands of pages of heterogeneous source material can be the difference between a thorough evaluation and one that proceeds on incomplete information.
Regulatory compliance and records management. Across all three industries, regulators require operators to maintain accurate, auditable records: in energy, that means well characteristics, completion details, and production history; in insurance, it means policy forms, claims files, and statutory filings; and in financial services, it means transaction records, fund documents, and investor communications. Because many of these records originate as paper or scanned images, automated extraction with source-level traceability reduces the manual burden of preparing regulatory submissions and ensures that the underlying data can be independently verified.
A Practical Path Forward
One of the advantages of modern document intelligence platforms is that they can be adopted incrementally, without requiring teams to overhaul their data infrastructure to start seeing value. A common entry point is to process a targeted set of high-priority documents, whether that is a batch of well files associated with an active development program, a backlog of insurance submissions awaiting underwriting review, or a financial data room for an in-progress transaction, validate the extraction quality against known benchmarks, and expand the scope from there.
The technology is also increasingly accessible through API-based delivery, which means it can be embedded into existing workflows and data pipelines without requiring teams to adopt an entirely new software environment, with extracted data flowing into the systems analysts and engineers already use, in the formats they already work with, bridging the gap between unstructured source documents and the structured data that drives decisions.
Regulated industries have spent decades accumulating documentary records that are, in aggregate, extraordinarily valuable, and the challenge has always been one of accessibility: how to convert that accumulated knowledge from static, unstructured formats into dynamic, analyzable data at a cost and speed that makes it practical. With vision-language models now capable of processing complex technical and financial documents at the accuracy levels these industries demand, the tools to unlock that value are finally here.
.svg)
