


Excel extraction is widely treated as the easy cousin of PDF extraction. Spreadsheets are structured, the reasoning goes, so a parser should be able to walk the grid, read the values, and emit clean tabular output. In practice, this framing is what causes most extraction systems to fail the moment they encounter a real enterprise workbook, because the structure that makes a spreadsheet a spreadsheet is precisely what naive extraction destroys.
The right starting assumption is that an Excel file is not structured data in any useful sense. It is a visual artifact whose meaning is encoded across a combination of layout, formatting conventions, and finance-specific notation that a model has to understand structurally rather than approximate. Two problems illustrate this well, and both are problems that production extraction systems get wrong on nearly every real workbook they encounter.
The Problem of Data the Source Is Hiding
The first problem is that real workbooks routinely contain data that is not visible when the file is opened. Columns can be hidden, rows can be hidden, and entire ranges can sit beyond the bounds of what the visible title or formatting suggests is the active region. This is not unusual or pathological behavior. It is how analysts manage the working complexity of a model that has internal calculations, intermediate metrics, or sensitivity scenarios that they do not want cluttering the main view but cannot delete because the model depends on them.
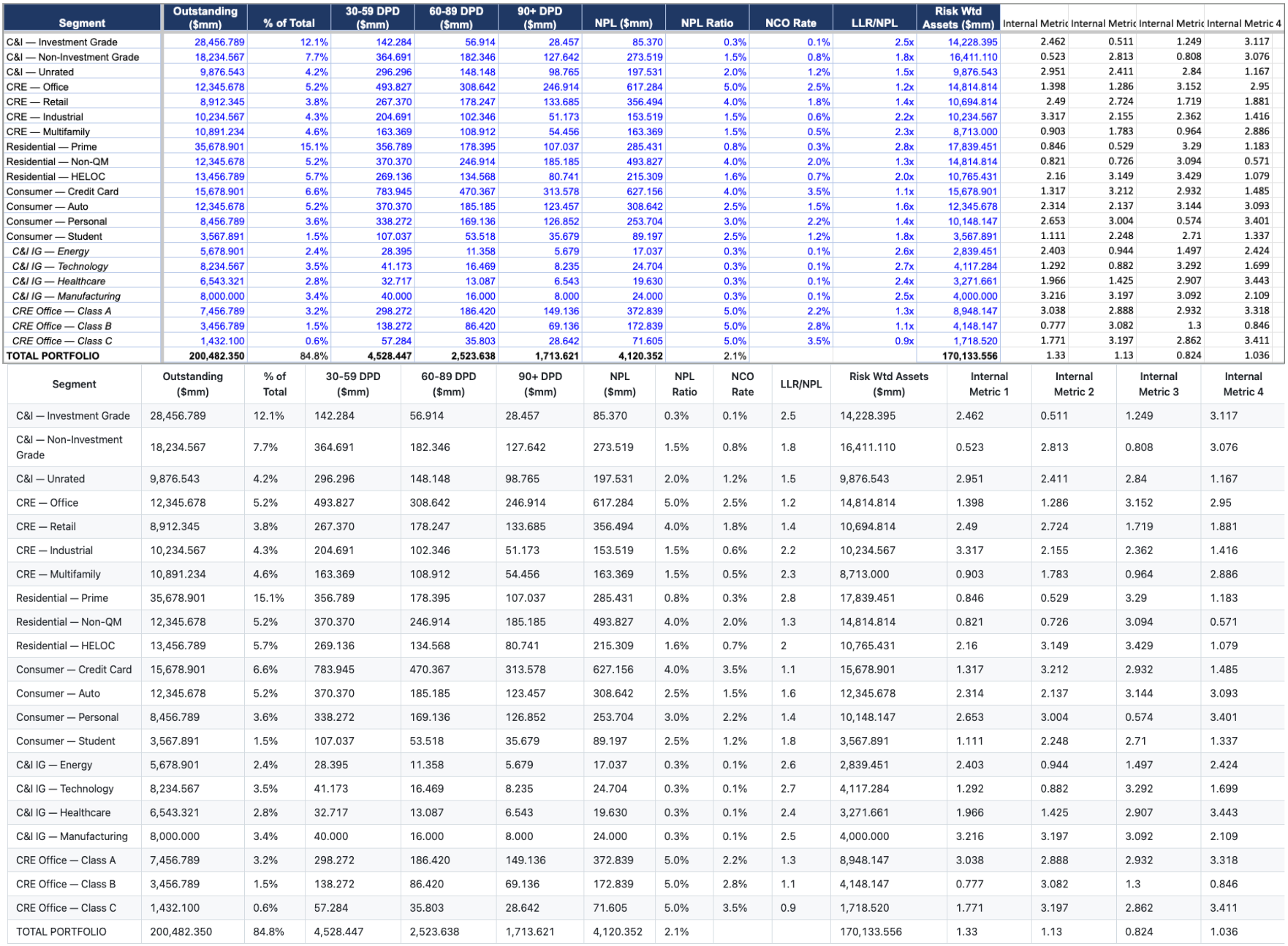
An extraction system has three reasonable choices when it encounters hidden data: surface it, exclude it, or surface it with an explicit flag indicating that it was hidden in the source. Any of those three can be the right answer depending on the downstream use case, but silently making the choice without telling the consumer is the wrong answer in every case, because a model that quietly drops hidden columns will miss real data, and a model that quietly includes hidden columns will smuggle internal-only metrics into output that was supposed to be customer-facing.
The reason this is hard is that it requires the extraction system to treat visibility as first-class metadata rather than as a property to be normalized away. Most systems normalize early, either by reading only what is visible or by reading everything indiscriminately, and in both cases the consumer of the output has no way to know which of the two happened. The right approach is to preserve the visibility state and let the consumer make an informed decision about what to do with it.
The Problem of Hierarchy Without Structure
The second problem is that workbooks routinely encode hierarchy through typographic conventions rather than through structural metadata. A balance sheet might list Investment Securities as a parent category and then list Trading Securities, Available-for-Sale, and Held-to-Maturity beneath it as indented sub-categories, and the only thing telling a reader that those three lines are children of Investment Securities is the leading whitespace in their labels. There are no merged cells, no outline groups, no structural indicators of any kind. The hierarchy lives entirely in the visual indentation.
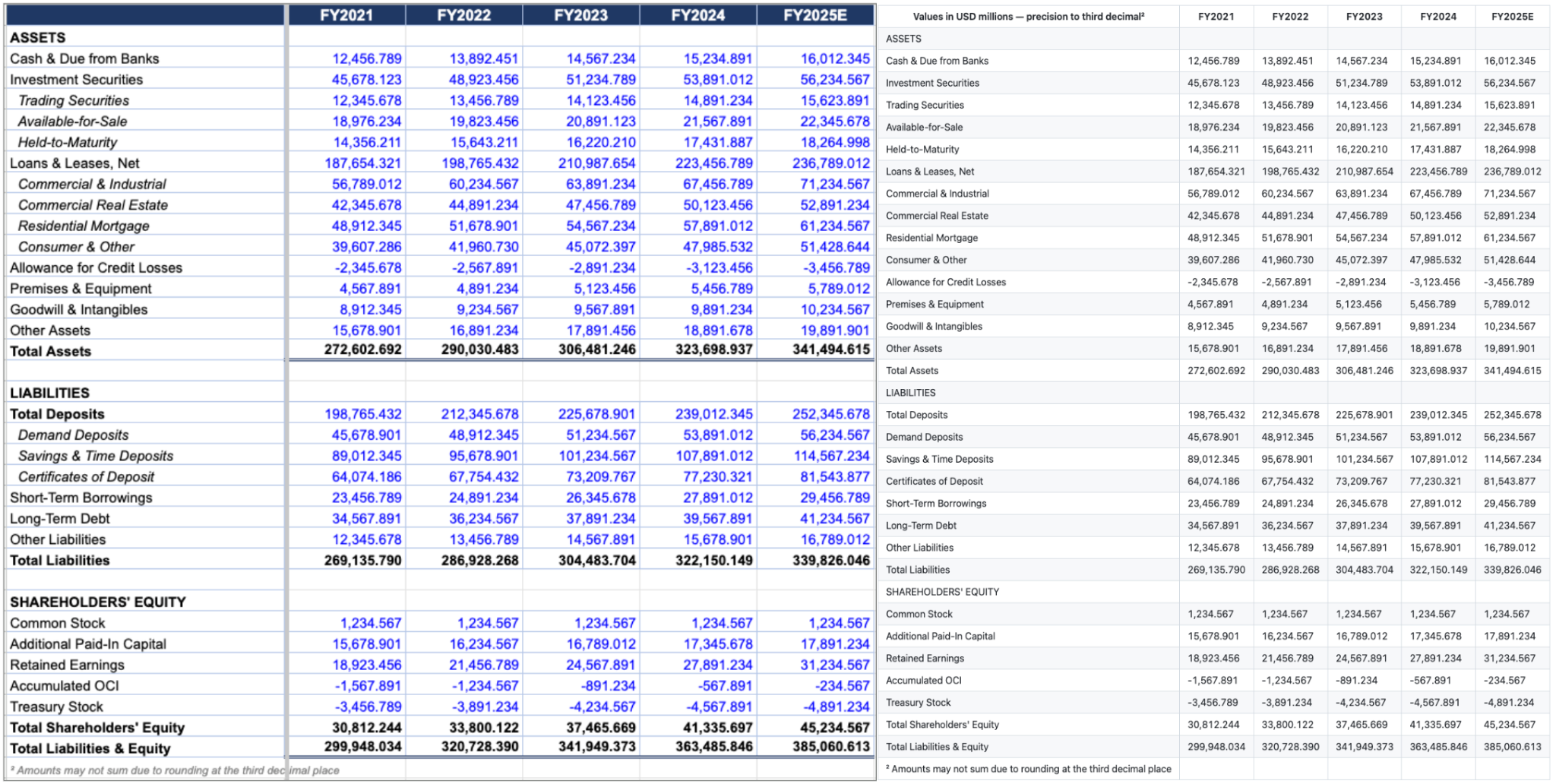
This is harder than the merged cell version of the same problem because there is no structural signal for the extraction system to preserve. The model has to recognize that leading whitespace in a label cell is semantically meaningful and that it encodes a parent-child relationship, and it has to carry that relationship through to the output in a form the downstream consumer can use. A system that strips the whitespace as if it were incidental formatting produces output where every line item appears to be at the same hierarchical level, which makes the resulting table arithmetically correct but structurally meaningless.
The principle underneath both problems is the same, which is that an extraction system has to treat conventions used by the workbook author as load-bearing rather than decorative. In finance, almost every visual convention is encoding something semantic, and the cost of normalizing it away is that the output looks plausible and is materially wrong.
Why This Matters for Production Deployments
The reason these two problems are worth dwelling on is that they are representative of a broader category, which is the gap between extraction that works in a demo and extraction that survives contact with production data. A demo workbook is usually clean, with no hidden data, no indented sub-categories, no merged headers, no accounting parentheses, and on that kind of input nearly every extraction system performs adequately. A real enterprise workbook contains all of these conventions and several more, and the systems that fall apart on production data are the ones that treated the demo as representative.
This is the gap that Pulse Ultra 2 was built to close, which is why it is the model deployed at megafunds and Fortune 50 companies where the cost of a silent extraction error is measured in millions of dollars or in regulatory exposure rather than in mild inconvenience. The principle behind the model is simple, which is that the extraction should preserve what the workbook author originally encoded rather than approximate it, and the engineering work of the last several months has been about making that principle hold across every category of failure that finance teams care about.

