


Commercial real estate runs on data, and much of that data lives in rent rolls. For lenders, asset managers, and portfolio operators, rent rolls are the foundation of underwriting decisions, portfolio monitoring, and valuation. Yet despite their importance, they remain one of the most technically difficult document types to extract data from accurately and at scale, and most teams significantly underestimate the reasons why.
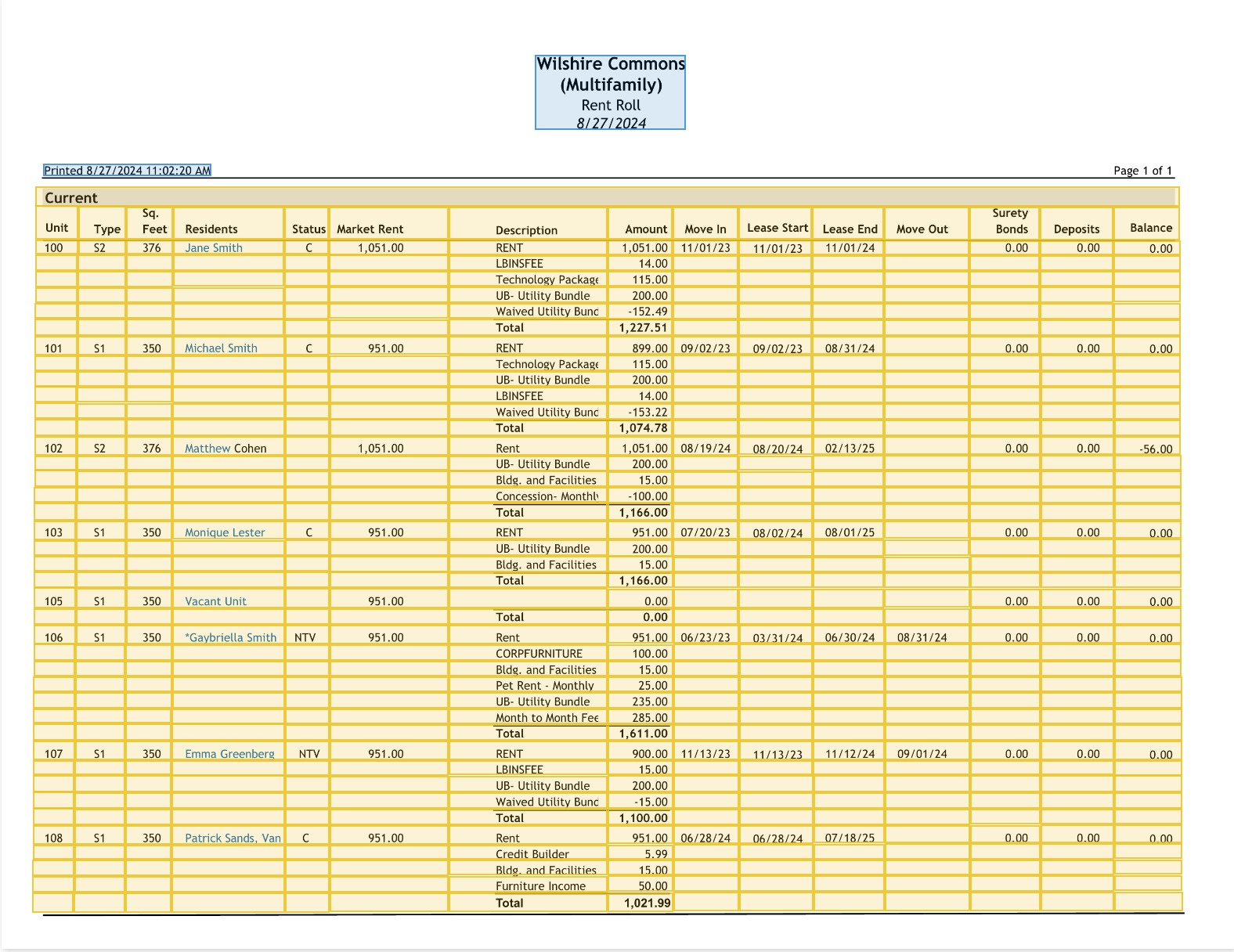
A sample rent roll processed by Pulse. Every cell is identified with word and cell level bounding boxes, preserving the structural relationships that traditional OCR systems routinely collapse.
Structural complexity is the real challenge
On the surface, a rent roll looks like a straightforward table, but in practice it is one of the most structurally demanding documents a data extraction system will encounter. Rent rolls are dense, with tightly packed text and intricate nested tables that require precise layout interpretation to parse correctly. They rely heavily on blank cells to convey meaning, and this is where most traditional OCR systems fail. When a system collapses or misrepresents a blank cell, it does not just lose a data point. It corrupts the structural integrity of the entire table, making the downstream data unreliable regardless of how accurately the text itself was read.
Tables frequently span multiple pages, with column headers that disappear mid-document and need to be intelligently reassociated. Rent rolls also rarely arrive as clean standalone files. They are typically embedded inside larger document packages alongside financial statements, property narratives, and market summaries, which means the system first needs to identify what to extract and from where before extraction can even begin.
Handling all of this correctly requires a pipeline that goes well beyond standard OCR, one that includes vision language models capable of interpreting document layout visually, layout understanding models that preserve row and column span relationships at the cell level, and the ability to reason about document structure before a single data point is extracted.
The format challenge compounds everything else.
Even once the structural challenges are addressed, there is the reality that no two rent rolls look the same. Property management platforms like MRI Software, Yardi, and RealPage each produce their own export formats, and within each of those platforms there are hundreds of configuration variants depending on how individual operators have set up their systems.
Template-based extraction requires predefining fields and their locations on the page, which becomes a maintenance burden at any meaningful portfolio scale and breaks entirely when a new format appears. Our client, one of the nation's leading CRE firms, processes rent rolls from hundreds of properties across their portfolio, and what made the difference was moving to a system that could adapt semantically to whatever format a document arrived in, without requiring reconfiguration every time something looked different.
What good extraction actually looks like.
When the extraction layer is built specifically for documents like rent rolls, the structural complexity stops being a bottleneck. Data comes out clean, structured, and auditable, with every extracted value traceable back to its exact location in the source document. Confidence scores flag where human review is warranted, which means human time is spent on the exceptions rather than the entire pipeline, and because the system generalizes across formats rather than relying on templates, it scales as your portfolio scales.
For firms operating at volume, the difference between getting this right and getting it wrong is not marginal. It is the difference between a data pipeline that can support growth and one that requires constant manual intervention to hold together.
If you are working through document extraction challenges in your CRE workflows and want to see how Pulse handles rent rolls on your specific documents, we would be glad to run a test on your end. Reach out to the team here to get started.

